
A Quick Reintroduction To Quality Indexation:
I’ve covered the importance of what I call “quality indexation” many times in my posts about major algorithm updates. It’s an extremely important topic, especially for larger-scale sites. When I refer to quality indexation, I’m referring to the importance of making sure your highest quality content gets indexed, while ensuring your low-quality or thin content remains out of the index. With Google confirming that it takes all pages indexed (10:06 in the video) into account when evaluating quality (25:20 in the video) for a site, it’s important to make sure your ratio is strong.
I see weak quality indexation rear its ugly head often while helping companies that have been negatively impacted by Google’s core algorithm updates. For example, there may be sections of a site containing massive amounts of indexed urls that are thin or low-quality. So the ratio of high quality content to low-quality content is not strong.
And when checking traffic to those areas from organic search, you don’t see much. So, you have massive indexation with low traffic levels from Google organic. That’s not a great combination for site owners and SEOs. I’ll provide more information about this soon.
In addition, this situation can cause crawl budget issues. Note, most sites (like 99.9%) don’t need to worry about crawl budget. But larger, more complex sites often do need to worry about it. For example, a large-scale site with millions of urls, and a complex setup, should definitely make sure crawl budget isn’t an issue. So, we have quality and crawl budget concerns when quality indexation is weak.
For example, here’s the coverage reporting for a large-scale site with millions of pages indexed and tens of millions of pages excluded. It’s extremely important for this site to focus on strong quality indexation:
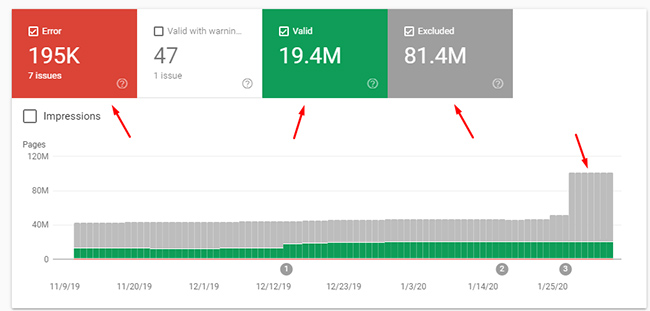
In worst-case scenarios, there may be millions, or tens of millions, of low-quality urls indexed that can end up dampening the quality of the site overall in Google’s eyes. I am working with a client now where this is the case. The good news is that we are actively working on fixing the situation once I uncovered the problem. The bad news is that this has been in place for a long time and Google will need to figure the changes out over time across tens of millions of urls. That said, the site owner wants to get the site in order for long-term success and understands this is the right way to proceed.
In this post, I’ll explain a process for identifying weak quality indexation across a large-scale site by directory. It’s a strong approach, especially when you’re dealing with a large and complex site.
Pre-Audit Analysis In GA and GSC:
Before fully digging into an audit, it’s always a good idea to spot-check certain reports in GSC, review the search history of the site, and more. You can sometimes find glaring issues that give you a hint about what’s going on with a site and why it has lost rankings.
For large-scale sites, GSC’s coverage report is gold. It reports on errors, pages indexed, and then contains an entire section for urls excluded from indexing. I’ve mentioned the coverage report many times in my posts about SEO and I can’t emphasize enough how powerful the reporting can be.
And when you combine the coverage report with data from the performance report, you can often identify problematic areas of the site from a quality indexation standpoint. For example, are there areas of a site with millions of pages indexed, yet those pages receive very little traffic (or no traffic)? If so, why?
And when checking the performance report, you can cross-reference Google Analytics data to see overall traffic to a page (or section) and isolate Google organic traffic. That can also help you figure out the importance and value of certain page types.
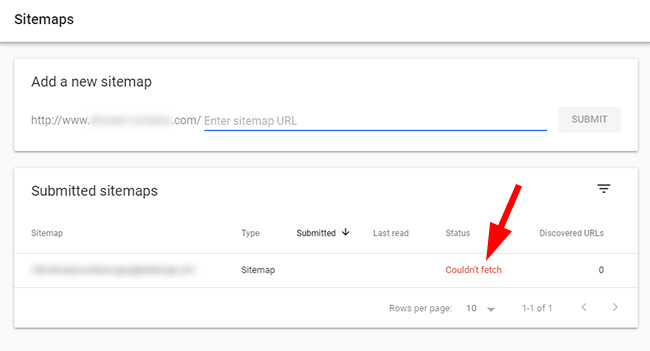
And if it’s a large-scale site with millions of urls, are xml sitemaps in order? How does indexation look when reviewing the coverage reporting for those sitemaps specifically (which you can do in GSC).
Google has explained that sitemaps are extremely important for larger-scale sites. For example, Google’s Gary Illyes said sitemaps are the second most-important source of URL discovery. In addition, John Mueller has explained that sitemaps can help Google understand canonical urls, when those urls change (by providing an accurate lastmod date per url), and more.
And all of what I mentioned above can help you answer a number of important questions. For example, should the pages be indexed or are they bogging down quality for the site? Are people even searching for topics that those pages could address? And can those pages meet or exceed expectations?
This process can often yield many pages that can be improved, or nuked from the site by either noindexing or 404ing the urls in question (if they simply shouldn’t be indexed). You can also find urls that should be canonicalized to other urls if they contain duplicate content. All of this is important to know so you can take action.
The Importance And Power Of Adding GSC Properties *By Directory*:
OK, so you now you’re excited to jump into GSC’s coverage report to begin some detective work. Well, I have some bad news for you. First, the coverage report will cover the entire site, so you can’t slice and dice your data by directory. Second, the reporting is limited to just one thousand urls per report. That’s clearly not sufficient when dealing with a site that contains millions of urls.
Note, I’ve repeatedly asked Googlers for an index coverage API so you can export all urls by report. I even did this in person at Google’s webmaster conference where I spoke with the GSC product team directly! I’m sad to say that I don’t believe it’s coming any time soon, so let’s move on.
So what’s a site owner to do when there are limitations like that?
Well, there’s a hack that works pretty darn well. And it can help you isolate problems per directory and gain a better understanding for quality indexation levels across each directory. The solution is adding properties to GSC for each directory. I’ve written a few blog posts about this topic and I always tell clients with larger-scale sites to set this up ASAP.
After adding each important directory to GSC, you can view the coverage and performance reporting JUST FOR THAT DIRECTORY. You can get a better feel for that directory by drilling into the various reporting without having to worry about the other directories muddying up the data.
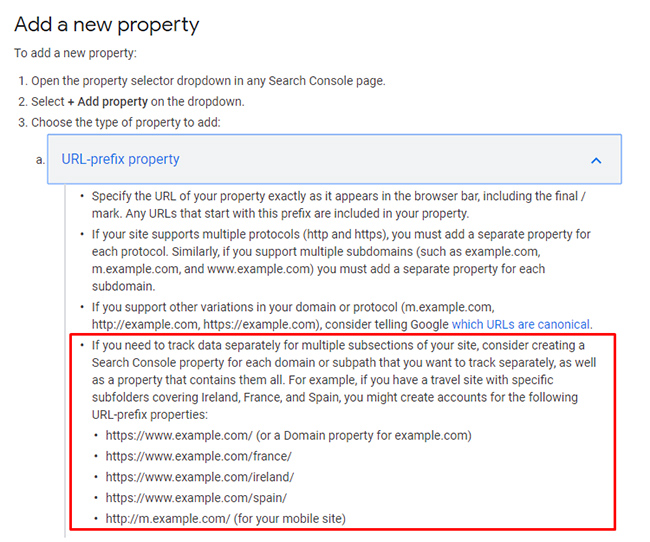
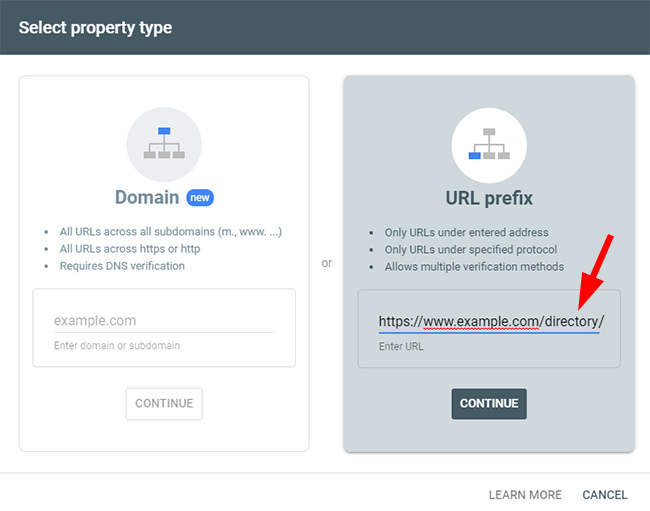
Case Study: Drill Into Directories And Let The Data Guide You
Back to the case study. Earlier I explained that I’m helping a client with a pretty serious quality indexation problem and it’s a great example of what I’ve explained so far in this post. By using the methods I covered, it was easy to identify problematic areas of the site where many pages were indexed, yet those areas received almost no organic search traffic.
And I’m not talking about a few thousand pages indexed here or there. I’m referring to millions of pages indexed with almost no organic search value at all. That helped us identify clear candidates for deindexing (either via noindexing, 404ing, or by canonicalizing urls that were duplicates).
Below, I’ll cover some quick examples of high indexation and low search value. I think you’ll get the picture pretty quickly. Let’s begin.
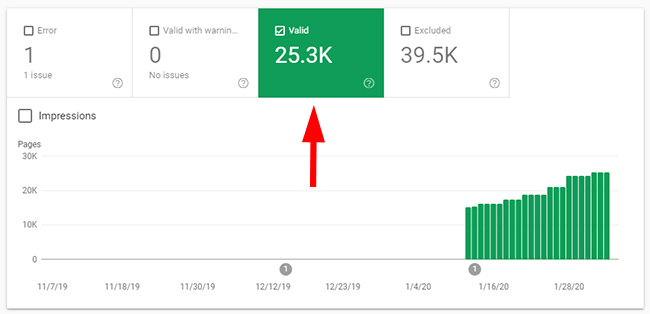
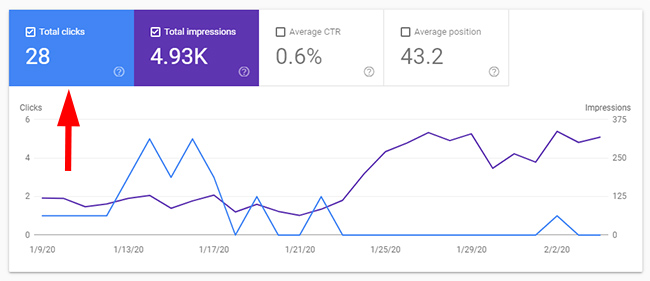
Directory One – Weak Quality Indexation
The directory contains pages targeting broad queries that this site will never rank for. It’s not even the main focus of the site. There are 25.3K pages indexed according to GSC, yet only 28 clicks. Yep, just 28. GA shows very low levels of traffic from Google organic as well.
Directory Two – Weaker Quality Indexation
The next directory that raised red flags yielded even weaker quality indexation levels. It also covered an area of content that was fine to have for users once they are on the site (it was tangentially relevant to the main topic for the site), but the content wasn’t great and many people wouldn’t even be searching for this type of information. There are 125K pages indexed in the directory, yet only 39 clicks in GSC.
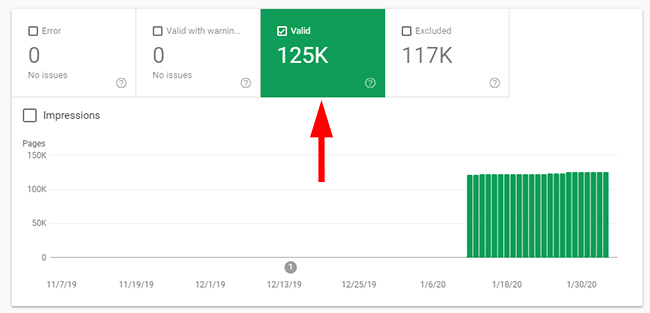
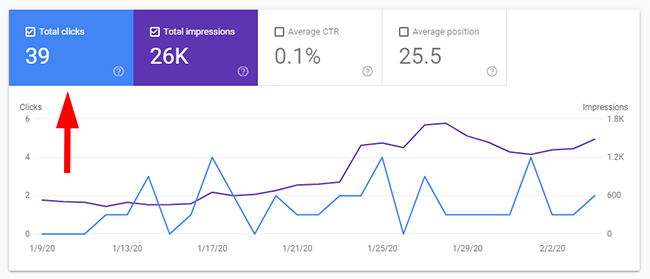
Directory Three – Duplicate content not handled properly.
The third directory I checked contained mass-duplicate content that was not being handled properly. For example, the urls should be canonicalized to the true canonical urls. There were 491K pages indexed in this directory, yet there were only 224 clicks during the time period.
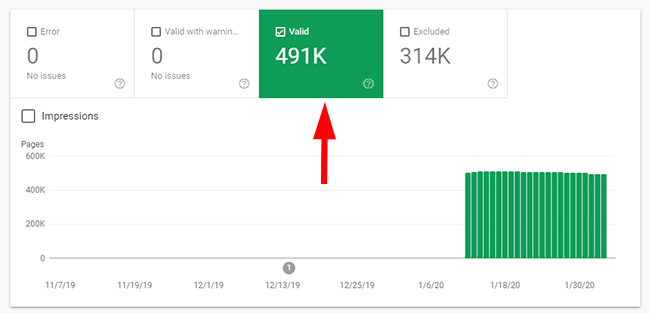
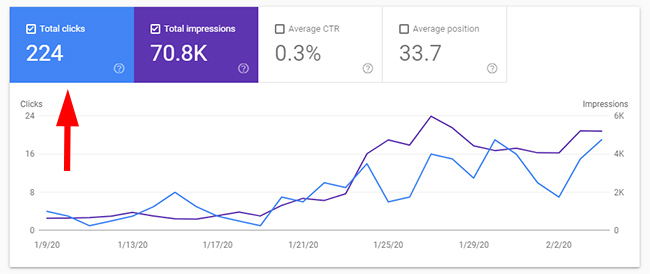
Directory Four – This is getting scary.
The next directory that I had concerns with had a whopping 3.04M pages indexed. It yielded more traffic than the previous three I checked, but still only 5.79K clicks. That’s not very much based on total indexation for the directory. Not good.
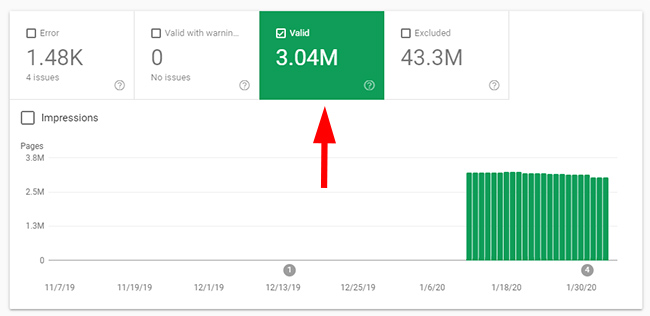
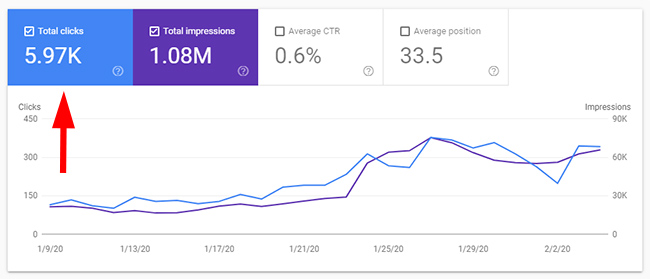
And with each additional directory I checked, I saw more of the same. Many pages indexed that weren’t yielding any (or much) organic search traffic. This was a great example of how weak quality indexation could bog down a site.
Moving Forward: Taking Action To Improve Quality Indexation
I’m working with the site owner to fix this situation as quickly as we can. Since it’s a huge site, this will take time to fix and then time for Google to reprocess the changes. Our goal is to make sure only the highest-quality pages are indexed while ensuring low-quality, thin, or duplicate content is handled properly from an SEO standpoint.
Below, I’ll end this post with some final tips and recommendations for enhancing quality indexation. Again, it’s an incredibly important topic for SEO.
Some tips and recommendations when investigating quality indexation problems:
- First, if you manage a large-scale site, make sure you focus on thoroughly understanding quality indexation levels across the site (by directory if you can). Don’t end up with many low-quality or thin pages indexed.
- As I covered earlier, definitely add GSC properties by directory if you can. That will enable you to isolate those directories and view all GSC reporting by that subfolder.
- Understand the organic search value for each directory. You can leverage both GSC and GA data to verify traffic per site section and compare that to indexation per directory. And you should crawl those areas to fully understand what’s going on there from a content standpoint, technical SEO standpoint, etc.
- Objectively analyze pages from each directory to understand the true value for the user. Ask yourself what would users search for to find that content? And if they find the content via Search, would it meet or exceed user expectations? If you’re having a hard time answering those questions, the pages could be good candidates for deindexing.
- Form a plan of attack for improving quality indexation across the site. And understand volatility will probably come along for the ride if you are implementing significant changes across a large-scale site. That said, do what’s best for the long-term health of the site.
- Track changes the best you can by documenting your coverage reporting and search analytics reporting over time. Coverage reporting is just for the past 90 days while search analytics data is for the past 16 months.
- Don’t forget to set up accurate and thorough xml sitemaps (especially for larger-scale sites). They can help on multiple levels as I mentioned earlier. And if you are running a large-scale site, use sitemap index files to make sure you have full coverage of your site’s canonical urls. Make sure lastmod dates are accurate and are updated whenever content significantly changes across pages.
Summary – Don’t let weak quality indexation drag down your site.
In this post, I documented a good case of a site dealing with quality indexation problems. And with Google confirming that every page indexed is taken into account when evaluating quality, having millions of additional low-quality or thin pages indexed is not a good thing.
If you manage a large-scale site, this can become especially dangerous SEO-wise. I recommend going through the process I documented above and surfacing quality indexation problems. Then you should address those problems efficiently to enhance the long-term health of the site. You might experience some volatility in the short-term, but your goal should be long-term SEO success. I would focus on that. Good luck.
GG