
So, how large is your site? No, how large is it really??
When speaking with companies about SEO, it’s not long before I ask that important question. And I often get some confused responses based on the “really” tag at the end. That’s because many site owners go by how many pages are indexed. i.e. We have 20K, 100K, or 1M pages indexed. Well, that’s obviously important, but what lies below the surface is also important. For example, Googlebot needs to crawl and process all of your crawlable urls, and not just what’s indexed.
Site owners can make it easy, or very hard, for Google to crawl, process, and index their pages based on a number of factors. For example, if you have one thousand pages indexed, but Google needs to crawl and process 600K pages, then you might have issues to smooth over from a technical SEO perspective. And when I say “process”, I mean understand what to do with your urls after crawling. For example, Google needs to process the meta robots tag, rel canonical, understand duplicate content, soft 404s, and more.
By the way, I’ll cover the reason I said you might need to smooth things over later in this post. There are times a site has many urls that need to be processed that are being properly handled. For example, noindexing many pages that are fine for users, but shouldn’t be indexed. That could be totally ok based on what the site is trying to accomplish. But on the flipside, there may be sites using a ton of parameters, session IDs, dynamically changing urls, or redirects that can cause all sorts of issues (like creating infinite spaces). Again, I’ll cover more about this soon.
And you definitely want to make Google’s job easier, and not harder. Google’s John Mueller has mentioned this a number of times over the past several years. Actually, here’s a video of John explaining this from last week’s webmaster hangout video. John explained that you don’t want to make Google’s job harder by having it churn through many urls. Google needs to crawl, and then process, all of those urls, even when rel canonical is used properly (since Google needs to first crawl each page to see rel canonical).
Here’s the clip from John (at 4:16 in the video):
John has also explained that you should make sure Google can focus on your highest quality content versus churning through many lower quality urls. That’s why it’s important to fully understand what’s indexed on your site. Google takes all pages into account when evaluating quality, so if you find a lot of urls that shouldn’t be indexed, take action on them.
Here’s another video from John about that (at 14:54 in the video):

Crawl Budget – Most don’t need to worry about this, but…
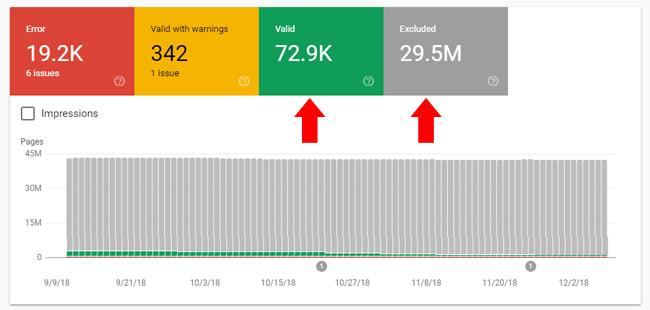
In addition, crawl budget might also be a consideration based on the true size of your site. For example, imagine you have 73K pages indexed and believe you don’t need to worry about crawl budget too much. Remember, only very large sites with millions of pages need to worry about crawl budget. But what if your 73K page site actually contains 29.5M pages that need to be crawled and processed? If that’s the case, then you actually do need to worry about crawl budget. This is just another reason to understand the true size of your site. See the screenshot below.
How Do You Find The True Size Of Your Site?
One of the easiest ways to determine the true size of your site is to use Google’s index coverage reporting, including the incredibly important Excluded category. Note, GSC’s index coverage reporting is by property… so make sure you check each property for your site (www, non-www, http, https, etc.)
Google’s Index Coverage
I wrote a post recently about juicing up your index coverage reporting using subdirectories where I explained the power of GSC’s new reporting. It replaces the index status report in the old GSC and contains extremely actionable data. There are multiple categories for each property in GSC in the reporting, including:
- Errors
- Valid with warnings
- Valid and indexed
- Excluded
By reviewing ALL of the categories, you can get a stronger feel for true size of your site. That true size might make total sense to you, but there are other times where the true size might scare you to death (and leave you scratching your head about why there are so many urls Google is crawling).
Below, I’ll run through some quick examples of what you can find in the index coverage reporting that could be increasing the size of your site from a crawling and processing standpoint. Note, there are many reasons you could be forcing Google to crawl and process many more pages than it should and I’ll provide just some quick examples in this post. I highly recommend going through your own reporting extensively to better understand your own situation.
Remember, you should make it easier on Googlebot, not harder. And you definitely want to have Google focus on your most important pages versus churning through loads of unimportant urls.
Errors
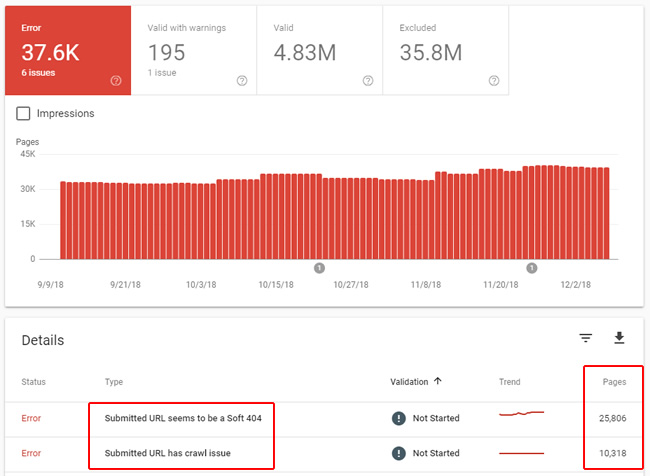
There are a number of errors that can show up in the reporting, including server errors (500s), redirect errors, urls submitted in sitemaps that are soft 404s, have crawl issues, are being blocked by robots.txt, and more. Since this post is about increasing the crawlable size of your site, I would definitely watch out for situations where Google is surfacing and crawling urls that should never be crawled (or urls that should resolve with 200s, but don’t for some reason).
There are also several reports in this category that flag urls being submitted in xml sitemaps that don’t resolve correctly. Definitely dig in there to see what’s going on.
Indexed and Valid
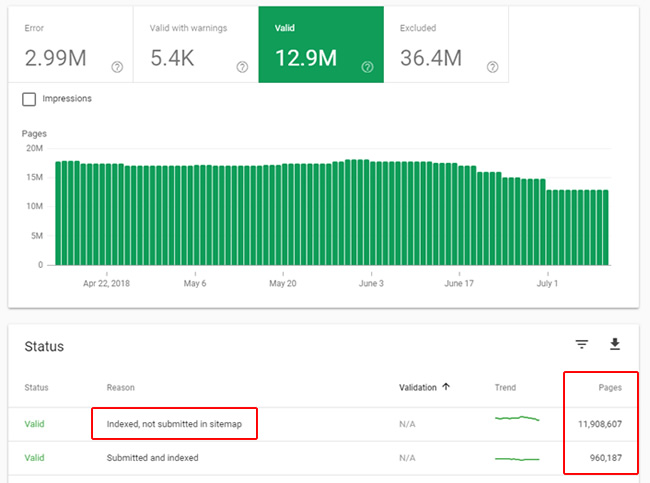
Although this report shows all urls that are properly indexed, you definitely want to dig into the report titled, “Indexed, not submitted in sitemap”. This report contains all urls that Google has indexed that weren’t submitted in xml sitemaps (so Google is coming across the urls via standard crawling without being supplied a list of urls). I’ve found this report can yield some very interesting findings.
For example, if you have 200K pages indexed, but only 4K are submitted in xml sitemaps, then what are the other 196K urls? How is Google discovering them? Are they canonical urls that you know about, and if so, should they be submitted in sitemaps? Or are they urls you didn’t even know existed, that contain low-quality content, or autogenerated content?
I’ve surfaced some nasty situations by checking this report. For example, hundreds of thousands of pages (or more) indexed that the site owner didn’t even know were being published on the site. Note, you can also fine some urls there that are fine, like pagination, but I would definitely analyze the reporting to gain a deeper understanding of all the valid and indexed urls that Google has found. Again, you should know all pages indexed on your site, especially ones that you haven’t added to xml sitemaps.
Excluded – The Mother Lode
I’ve mentioned the power of the Excluded category in GSC’s index coverage reporting before, and I’m not kidding. This category contains all of the urls that Google has crawled, but decided to exclude from indexing. You can often find glaring problems when digging into the various reports in this category.
I can’t cover everything you can find there, but I’ll provide a few examples of situations that could force Google to crawl and process many more urls than it should. And like John Mueller said in the videos I provided above, you should try and make it easy for Google, focus on your highest quality content, etc.
Infinite spaces
When I first fire up the index coverage reporting, I usually quickly check the total number of excluded urls. And there are times that number blows me away (especially knowing how large a site is supposed to be).
When checking the reporting, you definitely want to make sure there’s not an infinite spaces problem, which can cause an unlimited number of urls to be crawled by Google. I wrote a case study about an infinite spaces problem that was impacting up to ten million urls on a site. Yes, ten million.
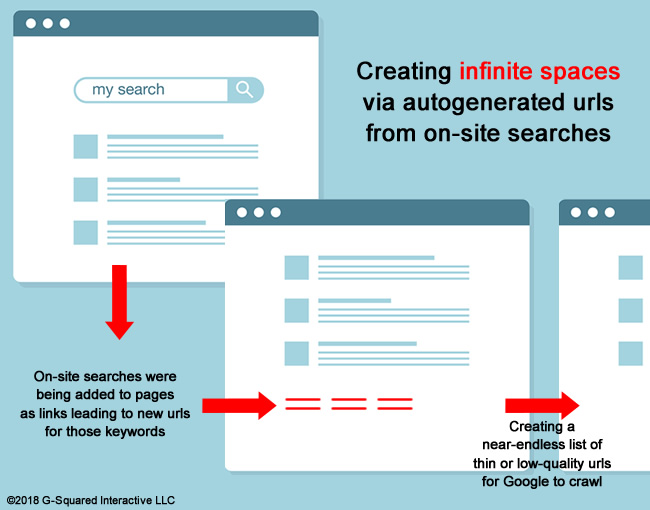
Sometimes a site has functionality that can create an unlimited number of urls with content that’s not unique or doesn’t provide any value. And when that happens, Google can crawl forever… By analyzing the Excluded category, you can potentially find problems like this in the various reports.
For example, you might see many urls being excluded in a specific section of the site that contain parameters used by certain functionality. The classic example is a calendar script, which if left in its raw form (and unblocked), can cause Google to crawl infinitely. You also might find new urls being created on the fly based on users conducting on-site searches (that was the problem I surfaced in my case study about infinite spaces). There are many ways infinite spaces can be created and you want to make sure that’s not a problem on your site.
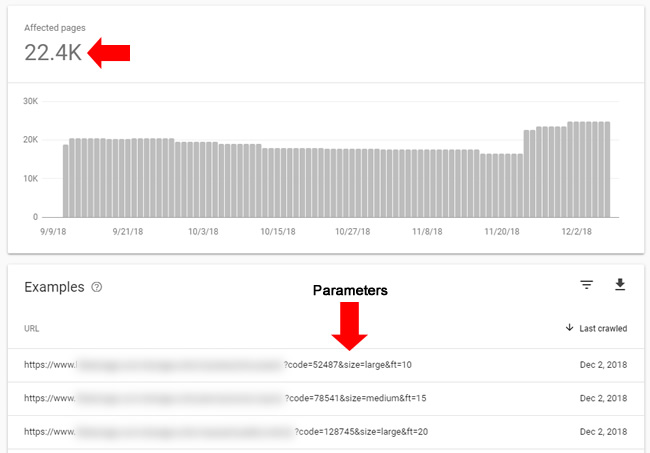
Parameters, parameters, parameters
Some sites employ a large number of url parameters, when those parameters might not be needed at all. And to make the situation worse, some sites might not be using rel canonical properly to canonicalize the urls with parameters to the correct urls (which might be the urls without parameters). And as John explained in the video from earlier, even if you are using rel canonical properly, it’s not optimal to force Google to crawl and process many unnecessary urls.
Or worse, maybe each of those urls with parameters (that are producing duplicate content) mistakenly contain self-referencing canonical tags. Then you are forcing Google to figure out that the urls are duplicates and then handle those urls properly. John explained that can take a long time when many urls are involved. Again, review your own reporting. You never know what you’re going to find.
When analyzing the Excluded reporting, you can find urls that fit this situation in a number of reports. For example, “Duplicate without user-selected canonical”, “Google chose a different canonical than user”, and others.
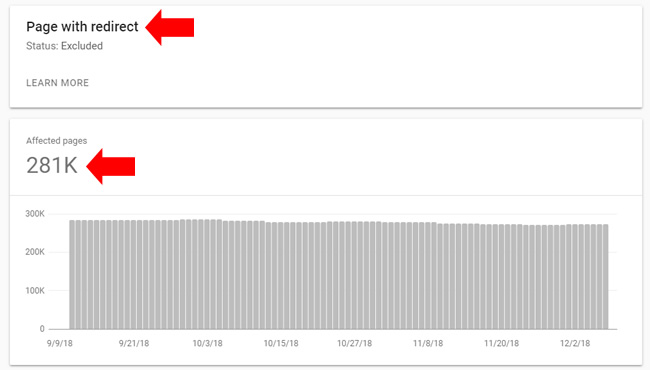
Excessive redirects
There are times you might find a massive number of redirects that you weren’t even aware were on the site. If you see a large number of redirects, then analyze those urls to see where they are being triggered on the site, why the redirects are there, and determine if they should be there at all. I wouldn’t force both users and Googlebot through an excessive number of redirects, if possible. Make it easy for Google, not harder.
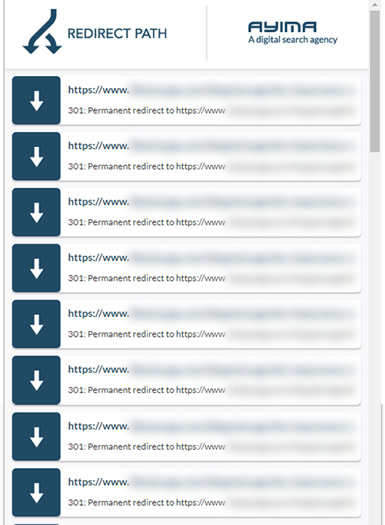
And some of those redirects might look like this… a chain of never-ending redirects (and the page never resolves). So one redirect might actually be 20 or more before the page finally fails…
Malformed URLs
There have been some audits where I find an excessive number of malformed urls when reviewing the Excluded reporting. For example, a coding glitch that combines urls by accident, leaves out parts of the url, or worse. And on a large-scale site, that can cause many, many malformed urls to be crawled by Google.
Here is an example of a malformed url pattern I surfaced in a recent audit:
https://www.domain.com/blog/category/some-blog-post-title/www.domain.com/blog/category/some-blog-post-title/www.domain.com/blog/category/some-blog-post-title/www.domain.com/blog/category/some-blog-post-title/www.domain.com/blog/category/some-blog-post-title/www.domain.com/blog/category/some-blog-post-title/www.domain.com/blog/category/some-blog-post-title/www.domain.com/blog/category/some-blog-post-title/www.domain.com/blog/category/some-blog-post-title/www.domain.com/blog/category/some-blog-post-title/
Soft 404s
You might find many soft 404s on a site, which are urls that return 200s, but Google sees them as 404s. There are a number of reasons this could be happening, including having pages that should contain products or listings, but simply return “No products found”, or “No listings found”. These are thin pages without any valuable content for users, and Google is basically seeing them as 404s (Page Not Found).
Note, soft 404s are treated as hard 404s, but why have Google crawl many of them when it doesn’t need to? And if this is due to some glitch, then you could continually force Google to crawl many of these urls.
Like I said, The Mother Lode…
I can keep going here, but this post would be huge. Again, there are many examples of problems you can find by analyzing the Excluded category in the new index coverage reporting. These were just a few examples I have come across when helping clients. The main point I’m trying to make is that you should heavily analyze your reporting to see the true size of your site. And if you find problems that are causing many more urls to be published than should be, then you should root out those problems and make crawling and processing easier for Google.

Sometimes Excluded can be fine: What you don’t need to worry about…
Not everything listed in the index coverage reporting is bad. There are several categories that are fine as long as you expect that behavior. For example, you might be noindexing many urls across the site since they are fine for users traversing the site, but you don’t want them indexed. That’s totally fine.
Or, you might be blocking 60K pages via robots.txt since there’s no reason for Googlebot to crawl them. That’s totally fine as well.
And how about 404s? There are some site owners that believe that 404s can hurt them SEO-wise. That’s not true. 404s (Page Not Found) are totally normal to have on a site. And for larger-scale sites, you might have tens of thousands, hundreds of thousands, or even a million plus 404s on your site. If those urls should 404, then that’s fine.
Here’s an example of a site I helped with many 404s at any given time. They do extremely well SEO-wise, but based on the nature of their site, they 404 a lot of urls over time. Again, this is totally fine if the urls should 404:
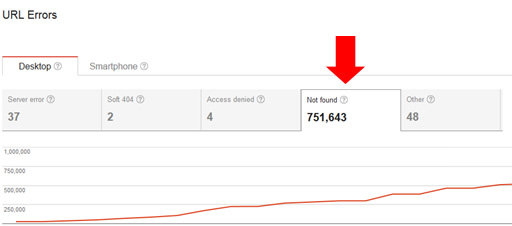
There have been several large-scale clients I’ve helped that receive over a million clicks per day from Google that have hundreds of thousands of 404s at any given time. Actually, a few of those clients sometimes have over one million 404s showing in GSC at any given time. And they are doing extremely well SEO-wise. Therefore, don’t worry about 404s if those pages should 404. Google’s John Mueller has covered this a number of times in the past.
Here’s a video of John explaining this (at 39:50 in the video):
There are other categories that might be fine too, based on how your own site works. So, dig into the reporting, identify anything out of the ordinary, and then analyze those situations to ensure that you’re making Google’s life easier, and not harder.
Index Coverage Limits And Running Crawls To Gain More Data
After reading this post, you might be excited to jump into GSC’s index coverage reporting to uncover the true size of your site. That’s great, but there’s something you need to know. Unfortunately, there’s a maximum one thousand rows per report that can be exported. So, you will be severely limited with the data you can export once you drill into a problem. Sure, you can (and should) identify patterns of issues across your site so you can tackle those problems at scale. But it still would be amazing to export all of the urls per report.
I know Google has mentioned the possibility of providing API access to the index coverage reporting, which would be amazing. Then you could export all of your data, not matter how many rows. In the short-term, you can read my post about how to add subdirectories to GSC in order to get more data in your reporting. It works well and you can read that post to learn more.
And beyond that, you can use any of the top crawling tools to launch surgical crawls into problematic areas. Or, you could just launch enterprise crawls that tackle most of the site in question. Then you can filter by problematic url type, parameter, etc. to surface more urls per category.
As I’ve mentioned many times in my posts, my three favorite crawling tools are:
- DeepCrawl (where I’m on the customer advisory board). I’ve been using DeepCrawl for a very long time and it’s especially powerful for larger-scale crawls.
- Screaming Frog – Another powerful tool that many in the industry use for crawling sites. Dan and his crew of amphibious SEOs do an excellent job at providing a boatload of functionality in a local crawler. I often use both DeepCrawl and Screaming Frog together. 1+1=3
- Sitebulb – The newest kid on the block across the three, but Patrick and Gareth have created something special with Sitebulb. It’s an excellent local crawling tool that some have described as beautiful mix between DeepCrawl and Screaming Frog. You should definitely check it out. I use all three extensively.
Summary – The importance of understanding the true size of your site.
The next time someone asks you how large your site is, try to avoid giving the quick response with simply pages indexed. If you’ve gone through the process I’ve documented in this post, the number might be much larger.
It’s definitely a nuanced answer, since Google might be churning through many additional urls based on your site structure, coding glitches, or other SEO problems. But you should have a solid grasp on what’s going on and how to address those issues if you’ve dug in heavily. I recommend analyzing GSC’s index coverage reporting today, including the powerful Excluded category. There may be some hidden treasures waiting for you. Go find them!
GG