
I recently started helping a new client that has seen a continued drop in search visibility over time. After getting up to speed on the site, its history, business model, etc., I started a thorough crawl analysis and audit of the site. The crawl analysis involves performing an enterprise crawl and then subsequent surgical crawls for areas I want to take a closer look at. I’ve always believed that crawling a site (just like Google does) could help surface potential gremlins that could be hurting a company’s SEO efforts. Unfortunately, what lies beneath from a technical SEO standpoint can sometimes be very scary. Problems invisible to the naked eye can fester over time. Well, this case is a great example of that happening.
Once the first crawls were completed across DeepCrawl, Screaming Frog, and Sitebulb, I quickly noticed something strange. I saw many 302 redirects on the site in the crawl data. It’s not unusual to pick up a number of redirects, but this just seemed higher than usual considering the number of pages present on the site. So I dug in further.
302 redirects *to the homepage*… and many of them
Once I dug into the data, I found thousands of 302 redirects all leading to the homepage. That concerned me on several levels. First, these were real pages with real content that were 302 redirecting to the homepage during the crawls. If you want those pages to rank well over the long-term, then 302 redirecting them is clearly not the route you want to take.
You are basically telling Google that the pages are temporarily being redirected to another page (which was the homepage in this case). And if Google sees 302s in place for a long enough time, then they can treat 302s as 301s. That means they would eventually just index the destination page(s) and drop the pages that are 302 redirecting. Google’s John Mueller has explained that several times in the past.
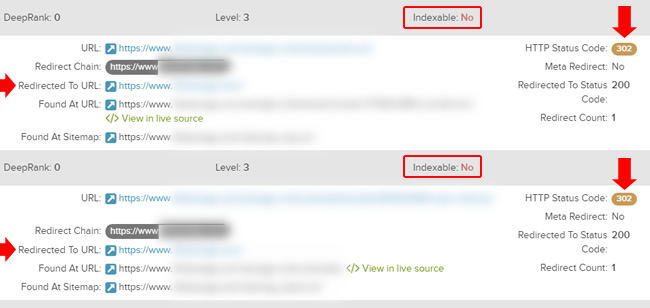
Triangulating The Problem Via Multiple Crawlers
After surfacing the 302 redirect problem, I manually started checking the redirects and noticed the pages were actually resolving with 200s when I checked them via a browser. That was strange… and I started to think that maybe the site was treating the crawlers differently and redirecting them for some reason. So I fired up all three crawls to check the data (across tools) to see if all were seeing the same problem. I wanted to triangulate the data.
Well, all three tools were showing the same thing. The site was indeed redirecting those urls to the homepage during crawling.

Therefore, manual checks were being handled correctly on the site (the pages were resolving fine), yet crawlers were sometimes being redirected via 302s to the homepage. That was clear across all three crawling tools I was using. Next up, I wanted to check the index coverage reporting in Google Search Console (GSC).
Yep, Index Coverage Also Revealed The Problem
The new index coverage reporting in GSC is awesome. It’s such a huge upgrade from the old index status report and provides a wealth of information directly from Google about crawling and indexing. Although there are several categories in the reporting, nothing comes close to the power of the Excluded category. That’s where you can view a series of reports containing urls that Google is excluding from indexing. And that’s also where you will find redirects. I fired up the reporting, jumped into the Excluded category and found the redirects report.
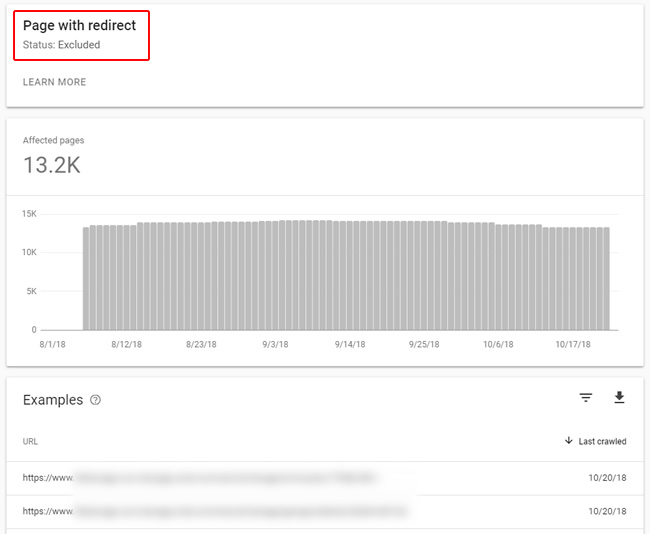
Note, although the new index coverage reporting is awesome, there is a slight problem… Unfortunately, you can only view and export the top one thousand listings in any report. That’s typically not even close to enough for larger-scale sites (see the screenshot above). So the Excluded reports contain incredibly actionable data, but it’s somewhat limiting due to the lack of (full) export functionality. Just keep that in mind when you are analyzing the reports.
Note, I know that the GSC team might be working on API access for the index coverage reports. That would be insanely awesome, and incredibly valuable. I hope that’s the case and I’ll be sure to share that news widely if that ever arrives.
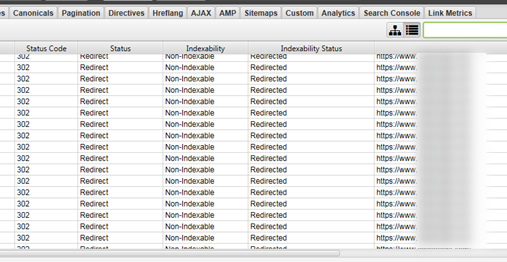
Back to the case study. So I checked a number of urls in the report and noticed they did resolve ok when checking them manually. Yet Googlebot was detecting redirects (so Google was running into the same problem that my crawlers were). Then I exported the top one thousand redirects from GSC and started crawling them just to see what my crawlers would return.
Yep, a number of them were 302 redirecting for my crawlers, but resolved with 200s when I manually checked them in a browser. So Googlebot was indeed coming across those 302s just like I was. This was an important find so I immediately crafted a document for my client.
Dev Team Zombie Hunters
After sending a document covering the 302 redirect problem in detail, my client sent that information along to the dev team. After digging into the issue, it ends up there was a load balancing issue that needed to be corrected. So the problem was indeed happening, but it was quietly occurring behind the scenes. It’s yet another example of a sinister SEO problem that can lie beneath the surface. What looks fine when visiting a site might be completely different when Googlebot visits the site. And that can end up very badly from an SEO standpoint.
So luckily, my client was able to push the SEO zombies back into the ground:

Based on this case study, and other sinister technical SEO problems I have surfaced in the past, I have provided some quick tips that might help your own situation.
- Crawl your site just like Google does, and do that on a regular basis. As demonstrated above, you never know what you’re going to find when crawling your site. Everything might be fine, but you might also surface new and serious problems. I recommend crawling your site monthly at a minimum.
- Always combine crawl data with a manual analysis. Validate what the crawl data is showing by testing the site manually and via multiple devices. Make sure you really have a problem and make sure Googlebot isn’t running into barriers.
- Triangulate the data via multiple crawling tools. I use three crawling tools extensively when auditing sites. That includes DeepCrawl (where I’m on the customer advisory board), Screaming Frog, and Sitebulb. All three are great and can help you confirm that a certain problem is indeed a problem.
- Don’t underestimate the power of Google’s index coverage reporting. It’s a powerful set of reports directly from Google covering information about how Googlebot crawls and indexes your site. In addition, the Excluded reporting contains information about urls that Google is excluding from indexing and often contains extremely actionable data. You can also use the inspect url tool to view the latest crawl information, as well as for testing live urls.
- Implement changes as quickly as you can once you surface problems like this. Technical SEO problems can cause all sorts of crawling, indexing, and ranking issues. The quicker you can rectify those problems, the faster you can recover. And if you haven’t been impacted yet rankings-wise, then you can nip serious SEO problems in the bud.
Summary – Crawlers + GSC Can Help Surface Sinister SEO Problems Invisible To The Naked Eye
Technical SEO is still incredibly important. And what lies beneath could be causing big problems from an SEO standpoint. For example, surfacing problems that Googlebot is encountering, that typical users aren’t, can help you avoid crawling, indexing, and ranking issues. If you’re proactive, and crawl your site on a regular basis, you can help keep the SEO zombies away.
Happy Halloween.
GG