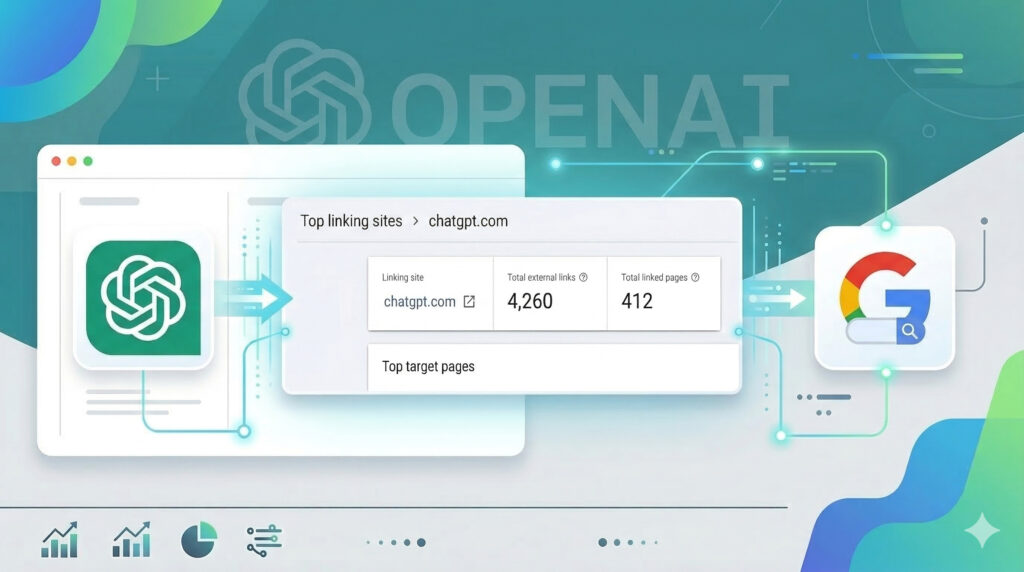
Reddit’s AI Translations Finally Drop Heavily In Google And AI Search With The May 2026 Core Update and June 2026 Spam Update
Reddit’s recent post about fighting spam was a bit suspect to me timing-wise, so I dug into the search visibility of its AI translations again. And yep, they finally starting dropping in Google and downstream in AI Search platforms like ChatGPT following the Google May 2026 core update and the June 2026 spam update. This … Read more