
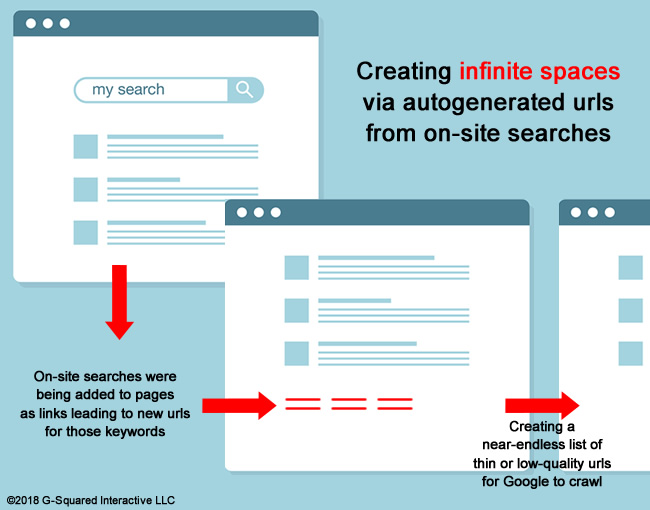
If you are working on a large-scale site, you need to be very careful that you don’t create infinite spaces. That’s when a site generates a near-endless list of urls that Google can end up crawling. Google does not want to churn through endless urls and it can cause problems on several levels SEO-wise. That’s why they detail infinite spaces in the search console help center and they also wrote a blog post specifically about the problem.
Google can end up wasting resources crawling many urls that are near-identical or low-quality. And that can flood Google’s index with thin and low-quality content.
During a recent audit on a site that has seen massive volatility over the past few years during major algorithm updates, I noticed a certain page type that I thought could be problematic. This was surfaced after the initial crawl (which was just a few hundred thousand urls out of 30+ million indexed). I saw enough of the problematic page type that I flagged it and then decided to dig in further.
The Core Problem: Autogenerating URLs
The core problem with the page type was that the site was autogenerating urls based on site searches, which ended up adding many thin or near-empty pages to the site (that were indexable). And even the urls that did contain some content didn’t really make sense to have on the site since they were so general (and even ridiculous in some cases). This created a near-infinite spaces situation with millions of urls being generated, and many of them with major quality problems.
I sent through initial findings to my client and we decided to get on a call to discuss the issue, along with a number of other important findings from my initial analysis. After speaking with my client and his tech lead, I found out the problem could be impacting up to 10 million urls. And with the site seeing major volatility during multiple major algorithms updates over the past several years, I couldn’t help but think the infinite spaces problem could be heavily contributing to that volatility.
To Infinity and… Behind? The Plan of Attack:
We quickly decided that I should dig into the situation full-blast to learn more about the autogenerated url problem. I literally left the call and started analyzing the pages using a number of tools. This was a process I’ve used a number of times before, so I thought it would be helpful to write a post covering it. It’s a strong way to use a powerful SEO software stack to surface and analyze an infinite spaces problem.
I’ll provide the process below, along with the SEO tools I used (which include both free and paid tools). The combination enabled me to tell a powerful story quickly and efficiently. My hope is that you can use this process, as well, in case you run across a problem that’s creating infinite spaces.
1) Starting with an enterprise crawl via DeepCrawl and Screaming Frog
The first step was running an enterprise crawl. The site has over 30 million pages indexed, but I almost never start by crawling millions of pages at once. You can definitely get a good feel for a site by crawling a few hundred thousand pages to start, and then perform surgical crawls based on problematic areas you surface. It’s a quicker and smarter way to crawl when you’re just starting an engagement.
The initial enterprise crawl helped surface many thin or near-empty pages, and those urls were the problematic page type I mentioned earlier. When digging into those urls, you could clearly see the infinite spaces problem, how the pages were being crafted, and how they were linking to more and more of the autogenerated urls.
I also ran a smaller crawl using Screaming Frog. I crawled 50K urls just to see what our amphibious friend would surface. And again, you could see the autogenerated results rearing its ugly head. So from a crawling perspective, there was a lot of evidence of the page type spawning many low-quality urls. Next up was to check traffic levels to the site for that page type.
Before moving on, I exported a filtered list of the problematic pages from the crawl data. You can do this in both DeepCrawl and Screaming Frog. You’ll need those urls for a step later in the process. More about that soon.
2) Google Analytics for trending and landing page data
My next move was to track trending over time to the problem urls to view how much traffic was being delivered there via Google organic search. I wanted to see how many of the pages were low-quality, how many were driving traffic versus the number indexed, was there serious volatility for the page type during major algorithm updates, and so on.
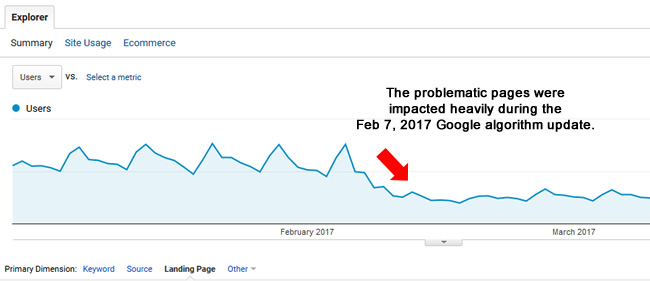
When checking trending overall, there was a clear drop from the February 7, 2017 update (which was a massive update). I wrote a post detailing that update, based on seeing a lot of volatility on sites across industries and countries. And when I isolated the problematic page type, the drop was even more distinct.
To isolate landing pages from Google organic, you can access Acquisition, All Traffic, Source/Medium, and then click on Google/Organic. Then you can dimension by landing page. But note, Google provides sampled data in this report for larger-scale sites. Just keep in mind that you are not seeing all of the data.
To view unsampled data, you can access Acquisition, All Traffic, Channels, Organic Search, and then dimension by landing page. But just keep in mind this report contains all organic search traffic and not just Google organic (although Google is a majority of organic search traffic for most sites).
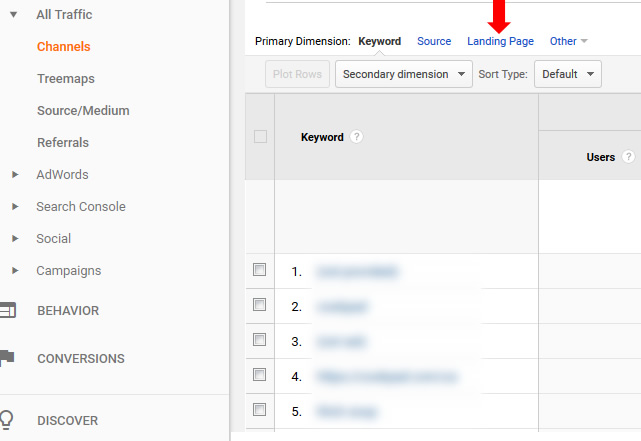
When checking landing pages from Google organic to the problematic page type, I found only 7K urls that were driving traffic from Google organic. That’s out of hundreds of thousands indexed in just one area of the site. That’s a huge red flag by the way. Google doesn’t believe the content is strong enough to rank and drive traffic to, yet those pages are clogging up the index with many low quality urls. Remember, this problem could be impacting up to 10 million urls when you take the entire site into account.
Export Time:
Also, it was important for me to gather as many landing pages as possible, so I could trigger a subsequent crawl of those urls. Therefore, I exported all of the problematic landing pages from Google Analytics (from organic search) for further analysis. For larger-scale sites, I use Analytics Edge which enables me to tap into the API and export urls in bulk. It’s an amazing solution that I use heavily. I’ve also written several posts about it over the years.
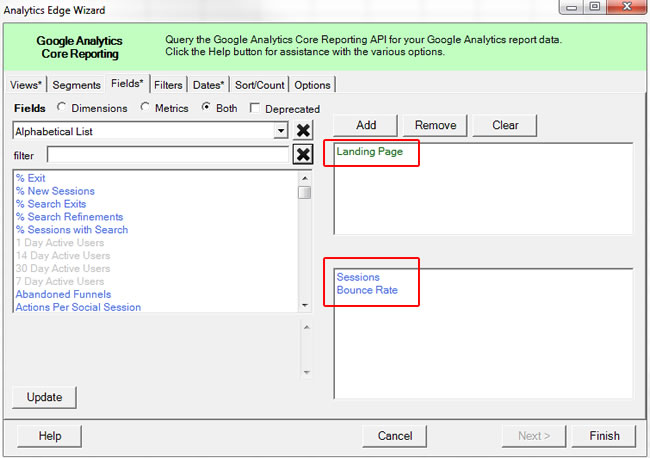
Optional Step: You can also run a medieval Panda report to see the drop after specific algorithm updates. That will enable you to see the landing pages from organic search seeing the largest drop after the update rolled out. You can often find glaring quality problems on those pages. You can learn more about running a Panda report in my tutorial. And no, it’s not just tied to Panda. It can be used for any traffic drop you are seeing.
3) GSC – The NEW Search Analytics Report (with 16 months of data)
The next step I took was to dig into the new search console reporting. All site owners now have access to the new GSC and it contains some extremely powerful reporting. It’s not complete yet, which is why you also have access to the old GSC at the same time.
First, you now have 16 months of data to analyze in the Performance reporting! That’s a new name for the Search Analytics report from the old GSC. Having 16 months of data is important and can help you view trending over a much longer period of time versus the old GSC (which was limited to just 90 days). You can also compare timeframes over a longer period of time.
If you have an infinite spaces problem, and you can isolate the page type via url structure, then the you can view trending of impressions and clicks over the past 16 months for the page type. That can also help you identify impact during major algorithm updates.
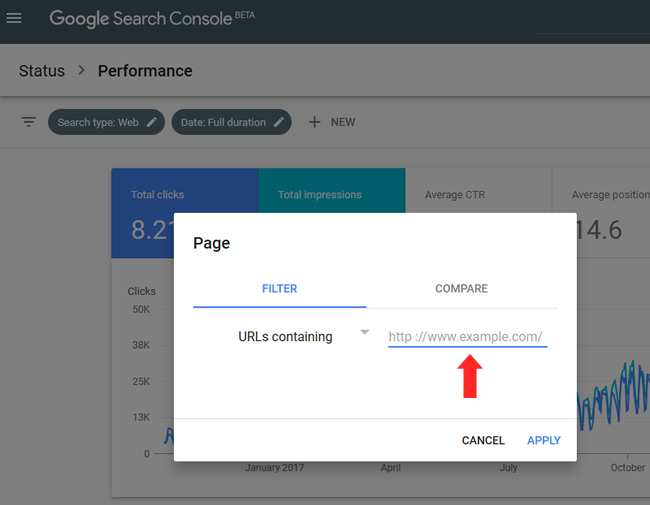
Exporting via the Search Analytics API (Using Analytics Edge):
In addition, you can export ALL of your landing pages for that page type via the GSC API. Remember, we’ll need those urls in order to create a master list of urls. I’ll cover the surgical crawl in a later step. Note, the UI in the Performance Report and Search Analytics report only lets you export one thousand urls, which is limiting for larger-scale sites. But using a solution like Analytics Edge enables you to fully export your landing pages. Again, you can read my tutorial to learn more.
Just understand that the Search Analytics API only goes back 90 days for now. I believe Google is working on extending that to the 16-month timeframe soon. But at least you can get a feel for how many landing pages from Google organic fit under the problematic page type that’s creating infinite spaces.
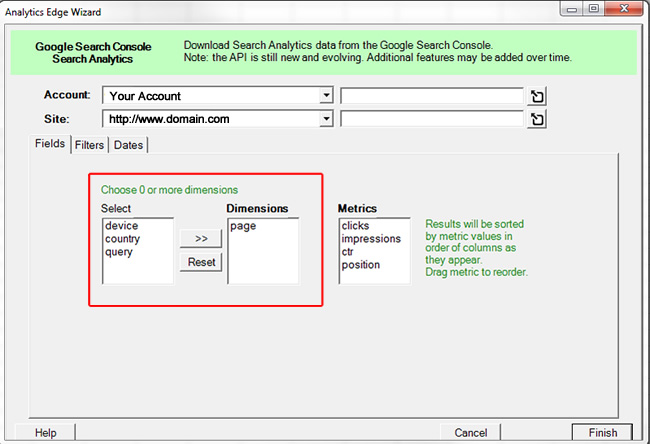
4) Index Coverage – Excluded and Valid
As part of the new GSC, Google provides one of the most powerful new tools for site owners and SEOs. It’s called Index Coverage and it’s the old Index Status report on steroids. I’m part of the GSC beta group and I’ve been testing this for a while before the official launch. I can tell you, the reporting is packed with actionable data.
For example, you can drill into the pages that are valid and indexed, you can view errors by category, and you can view urls that have been excluded by Google by category. Yes, you are getting a rare view into how Google is treating urls and page types across your site. We have been asking for this type of reporting for a long time and the Index Coverage report delivers – big-time!
For our purposes today, we’ll focus on the Excluded and Valid categories. Since I knew there were many thin and low-quality pages due to the infinite spaces problem, I wanted to see how many were showing as being excluded by Google (essentially letting me know that Google decided to not index the urls for some reason).
It didn’t take long to see the problematic page type showing up in a number of reports. For example, the Soft 404s report had many of the urls in them. That’s because there were many urls being autogenerated without any content.
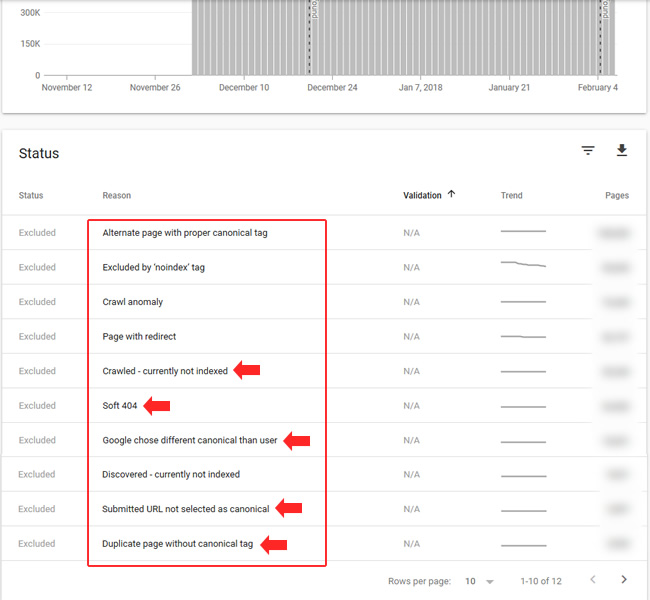
In addition, there were many showing up in the “submitted, but not indexed” category. Again, the site is providing the urls to Google (via sitemaps and via the internal navigation), yet Google has decided not to index many of them. It’s just more ammunition to take to your client, internal teams, etc. about the infinite spaces problem (if you need more ammunition).
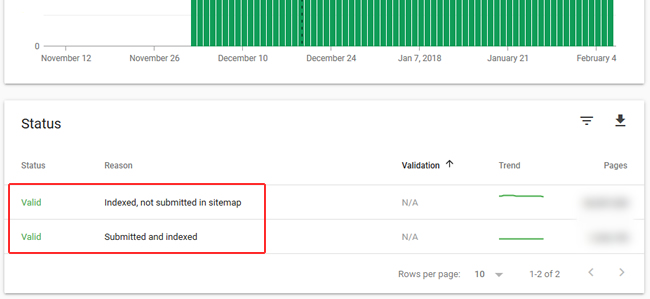
Beyond the Excluded category, you can check the Valid category in the Index Coverage reporting and filter by the problematic page type to see how many of those pages are indexed.
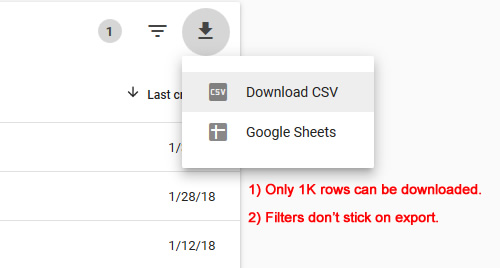
Export Time: You can export urls per category in the new GSC. That’s awesome, but there are limitations you should be aware of. First, you can only export up to one thousand urls per report (unlike the Search Analytics API, which lets you export the whole enchilada). I would have to check with Google again, but I believe they are working on adding API access for the Index Coverage report. I’ll update this post after finding out more.
Second, your filters don’t stick when exporting, and that’s problematic given what we’re trying to do here. Since we are filtering by page type, it would be awesome for the export to isolate those pages. But it doesn’t right now. All of the top one thousand urls are exported per category versus just the problematic page types. I submitted feedback to the GSC product team about this, so we’ll see if the export functionality changes. But for now, the Index Coverage report is for analyzing the page type, while the Search Analytics API can be used for full exports.
5) Deduping landing pages, preparing for the surgical crawl
At this point, you should have analyzed trending for the specific page type and you have exported urls along the way. Now it’s time to create a master list of problematic urls so you can perform a surgical crawl. The surgical crawl will enable you to get a close-up view of the problem, along with any other issues plaguing that page type.
Excel is your friend for this task. Create a new spreadsheet and copy all of the worksheets you exported into that document. For example, you’ll use the Move or Copy functionality to copy the worksheet to our new document. Just right click on a worksheet tab and you’ll see “Move or Copy”.
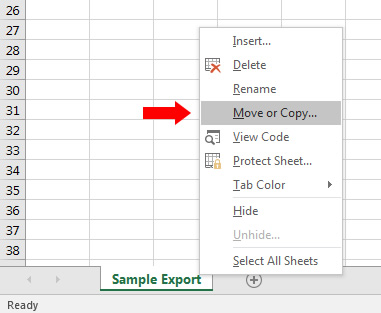
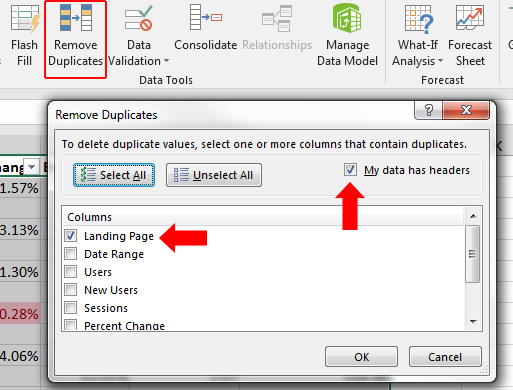
Then create a new worksheet that contains all of the urls listed together. Since there will be overlap, you want to dedupe that list before crawling the urls. Click Data, and the Remove Duplicates. If you have a header row, make sure to check that box. Once you click OK, Excel will remove any duplicate urls. Now you have your final list for the surgical crawl.
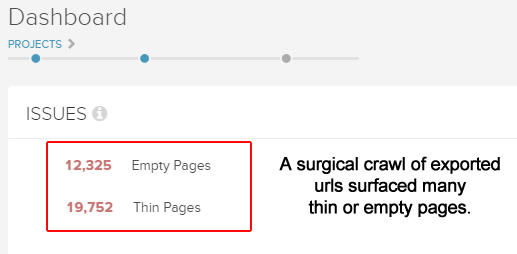
6) Perform a surgical crawl of JUST problematic urls
Depending on how many urls you have, you can choose to run the crawl via an enterprise crawler like DeepCrawl or via a desktop crawler like Screaming Frog. You could also choose to run a large-scale crawl of all the urls via DeepCrawl while crawling a subset of the urls via Screaming Frog (just to get a look at the urls via both tools).
Once the crawls complete, you can dig into the data to surface problems.
For example, you might (and probably will) find massive quality problems, thin content, empty pages, canonical issues, duplication, and more. And remember, this is just a subset of the total pages indexed for the problematic page type! Again, this is more ammo for your conversation with the various teams at your company or with your client.
Next Steps – Preparing for battle and crafting your strategy
At this stage, you should have a boatload of intelligence about your infinite spaces problem. Every step you took will help you document the problem from several angles. And once you convey the situation to your client, dev team, c-level executives, etc., you need to tackle the problem head-on.
That includes deindexing as many of those urls as possible and then stopping the problem from surfacing again. That last part could include multiple steps, including changing functionality on the site and handling the urls via robots.txt. It depends on what you find based on your analysis.
For my situation, there was clearly a problem with the site autogenerating many urls. And only a small fraction of the urls are receiving traffic. Many of those pages are thin or low-quality. And the site can generate a near-endless list of these urls. I’m working with my client now on the final strategy, which will undoubtedly include deindexing many urls, refining functionality on the site that’s creating infinite spaces, and then disallowing urls from being crawled in the future.
But there are some important points to understand about this process. First, watch out for simply disallowing via robots.txt. I know many would move to do that immediately, but that’s not necessarily the best move right out of the gates. If you want to deindex the urls via noindexing or 404s/410s, which you should, then Googlebot wouldn’t be able to see the meta robots tag using noindex (or the 404s/410s) if you disallow via robots.txt.
I recommend keeping the directory open and letting Google deindex them over the long-term. Then you can disallow via robots.txt once they have been removed. That can take a while, so be patient. You can read my case study about removing a rogue subdomain to learn more about that.
Also, if the urls are in specific directories, then you could add those directories to GSC as a property. Then you could use the new Index Coverage and the old Index Status reports to monitor indexation. Many still don’t know that you can add directories as properties in GSC. I recommend doing that.
XML sitemaps can help:
Also, you could submit xml sitemaps with all the problematic urls you collected and then check the new Index Coverage report for indexation, errors, etc. This is another benefit of exporting and deduping all of the problematic pages from DeepCrawl, Screaming Frog, Google Analytics, Search Analytics in GSC, and then Index Coverage in GSC. It’s totally fine to temporarily submit a sitemap that leads to 404s, 410s, or pages being noindexed. That can help Google with discovery and could lead to quicker deindexation.
Clarifying the Remove URLs Tool in GSC:
You can also choose to remove the urls via the Remove URLs Tool in GSC (especially if they are in a specific directory). But be aware that the Remove URLs tool does not work the way that many think it does. It’s a temporary removal (90 days) and only removes the urls from the search results (and not Google’s index).
You still need to actually remove the pages via 404, 410, or the meta robots tag using noindex for the pages to truly be removed. That’s extremely important to know, or you can end up in the same situation you were in when you started if you don’t handle the urls at the root. For an infinite spaces situation, you could temporarily remove the urls via GSC so they don’t show in the search results, while at the same time handle them on the site via 404s, 410s, or by using the meta robots tag using noindex.
Summary – Don’t let infinite spaces get in your way SEO-wise
Again, creating infinite spaces can be a dangerous thing from an SEO perspective, as Google can end up crawling a near-endless list of low quality, thin, or similar urls. It’s important to surface the problem and the urls being generated in order to properly tackle the situation.
Using a powerful SEO software stack, you can identify, analyze, and then address the problem efficiently. If you feel you have an infinite spaces problem (or might have one), I recommend following the process I provided in this post soon. Don’t let infinite spaces negatively impact your site SEO-wise. You can start today by “measuring infinity”. Good luck.
GG