
During a recent crawl analysis and audit of a large-scale site that was negatively impacted by Google’s core updates, I surfaced an interesting SEO problem. I found many thinner and low-quality pages that were being canonicalized to other stronger pages, but the pages didn’t contain equivalent content. As soon as I saw that, I had a feeling what I would see next… since it’s something I have witnessed a number of times before.
Many of the lower-quality pages that were being canonicalized were actually being indexed. Google was simply ignoring rel canonical since the pages didn’t contain equivalent content. That can absolutely happen and I documented that in a case study a few years ago. And when that happens on a large-scale site, thousands of lower-quality pages can get indexed (without the site owner even knowing that’s happening).
For example, imagine a problematic page type that might account for 50K, 100K, or more pages indexed. And when Google takes every page indexed into account when evaluating quality, you can have a big problem on your hands.
In the screenshot below, you can see that Google was ignoring the user-declared canonical and selecting the inspected url instead. Not good:
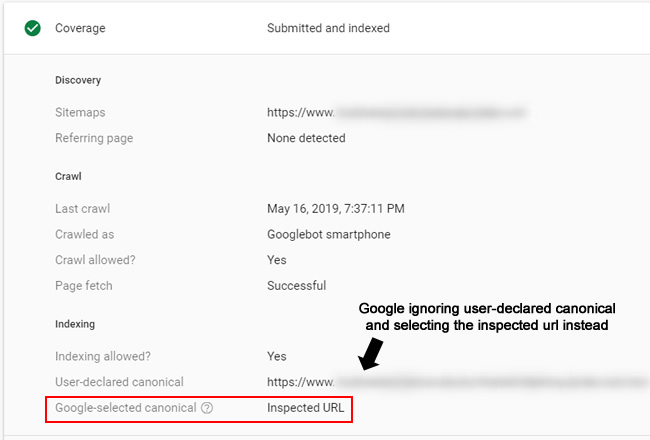
In addition to just getting indexed, those lower-quality pages might even be ranking in the search results for queries and users could be visiting those pages by mistake. Imagine they are thin, lower-quality pages that can’t meet or exceed user expectations. Or maybe they are ranking instead of the pages you intend to rank for those queries. In a case like that, the problematic pages are the ones winning in the SERPs for some reason, which is leading to a poor user experience. That’s a double whammy SEO-wise.
Quickly Estimating The Severity Of The Problem
After uncovering the problem I mentioned above, I wanted to quickly gauge how bad of a situation my client was facing. To do that, I wanted to estimate the number of problematic pages indexed, including how many were ranking and driving traffic from Google. This would help build a case for handling the issue sooner than later.
Unfortunately, the problematic pages weren’t all in one directory so I needed to get creative in order to drill into that data (via filtering, regex, etc.) This can be the case when the urls contain certain parameters or patterns of characters like numerical sequences or some other identifying pattern.
In this post, I’ll cover a process I used for roughly discovering how big of an indexing problem a site had with problematic page types (even when it’s hard to isolate the page type by directory). The process will also reveal how many pages are currently ranking and driving traffic from Google organic. By the end, you’ll have enough data to tell an interesting SEO story, which can help make your case for prioritizing the problem.
A Note About Rel Canonical – IT’S A HINT, NOT A DIRECTIVE
For any site owner that’s mass-canonicalizing lower-quality pages to non-equivalent pages, then this section of my post is extremely important. For example, if you think you have a similar situation to what I mentioned earlier and you’re saying, “we’re fine since we’re handling the lower-quality pages via rel canonical…”, then I’ve got some potentially bad news for you.
As mentioned earlier, rel canonical is just a hint, and not a directive. Google can, and will, ignore rel canonical if the pages don’t contain equivalent content (or extremely similar content). Again, I wrote a case study about that exact situation where Google was simply ignoring rel canonical and indexing many of those pages. Google’s John Mueller has explained this many times as well during webmaster hangout videos and on Twitter.

And if Google is ignoring rel canonical on a large-scale site, then you can absolutely run into a situation where many lower-quality or thin pages are getting indexed. And remember, Google takes all pages indexed into account when evaluating quality on a site. Therefore, don’t just blindly rely on rel canonical. It might not work out well for you.
Walking through an example (based on a real-world situation I just dealt with):
To quickly summarize the situation I surfaced recently, there are tens of thousands of pages being canonicalized to other pages on the site that aren’t equivalent content-wise. Many were being indexed since Google was ignoring rel canonical. Unfortunately, the pages weren’t located in a specific directory, so it was hard to isolate them without getting creative. The urls did contain a pattern, which I’ll cover soon.
My goal was to estimate how many pages were indexed and how many were ranking and driving traffic from Google organic. Remember, just finding pages ranking and driving traffic isn’t enough, since there could be many pages indexed that aren’t ranking in the SERPs. Those are still problematic from an SEO standpoint.
The data would help build a case for prioritizing the situation (so my client could fix the problem sooner than later). It’s a large-scale with many moving parts, so it’s not like you can just take action without making a strong case. Volatility-wise, the site was impacted by a recent core update and there could be thousands (or more) lower-quality or thin pages indexed that shouldn’t be.
With that out of the way, let’s dig in.
Gauging The Situation & The Limits Of GSC
To gauge the situation, it’s important to understand how big of a problem there is currently and then form a plan of attack for properly tackling the issue. In order to do this, we’ll need to rely on several tools and methods. If you have a smaller site, you can get away with just using Google Search Console (GSC) and Google Analytics (GA). But for larger-scale sites, you might need to get creative in order to surface the data. I’ll explain more about why in the following sections.
Index Coverage in GSC – The Diet Coke of indexing data.
The index coverage reporting in GSC is awesome and enables you to view a number of important reports directly from Google. You can view errors, warnings, pages indexed, and then a list of reports covering pages that are being excluded from indexing. You can often find glaring issues in those reports based on Google crawling your site.
Based on what we’re trying to surface, you might think you can go directly to the Valid (and Indexed) report, export all pages indexed, then filter by problematic page type, and that would do the trick. Well, if you have a site with less than 1,000 pages indexed, you’re in luck. You can do just that. But if you have more than 1,000 pages, then you’re out of luck.
GSC’s Index Coverage reporting only provides 1,000 urls per report and there’s no API (yet) for bulk exporting data. Needless to say, this is extremely limiting for large-scale sites. To quote Dr. Evil, it’s like the Diet Coke of indexing data. Just one calorie… not thorough enough.

Search Console API & Analytics Edge
Even though exporting urls from the Valid (and Indexed) category of index coverage isn’t sufficient for larger-scale sites, you can still tap into the Search Console API to bulk export Search Analytics data. That will enable you to export all landing pages from organic search over the past 16 months that have impressions or clicks (basically pages that were ranking and driving traffic from Google). That’s a good start since if a page is ranking in Google, it must be indexed. We still want data about pages indexed that aren’t ranking, but again, it’s a start.
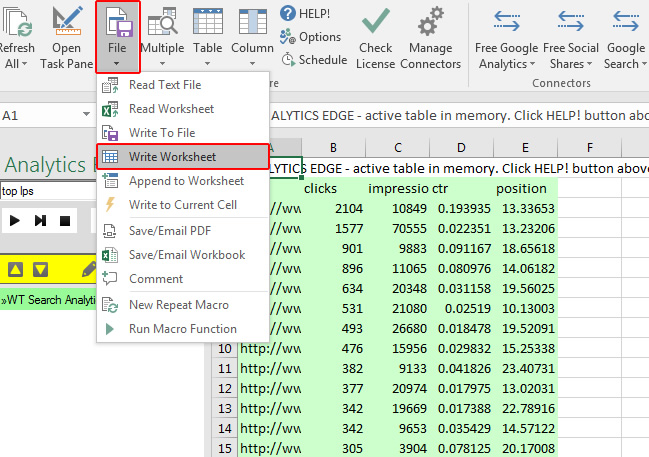
My favorite tool for bulk exporting data from GSC is Analytics Edge. I’ve written about Analytics Edge multiple times and you should definitely check out those posts to get familiar with the Excel plugin. It’s powerful, quick, reasonably priced, and works like a charm.
For our situation, it would be great to find out how many of those problematic pages are gaining impressions and clicks in Google organic. Since the pages are hard to isolate by directory or site section, we can export all landing pages from GSC and then use Excel to slice and dice the data via filtering. You can also use the Analytics Edge Core Add-in to use regex while you’re in the process of exporting data (all in one shot). More about that soon.
A Note About Regex For Slicing And Dicing The Data
Since the pages aren’t in one directory, using regular expressions (regex) is killer here. Then you can filter using regular expressions that target certain url patterns (like isolating parameters or a sequence of characters). To do this, you can use the Analytics Edge Core Plugin in conjunction with the Search Console connector so you can export the list of urls AND filter by a regular expression all in one macro.
I won’t cover how to do that in this post, since that can be its own post… but I wanted to make sure you understood using regex was possible.
You can also use Data Studio and filter based on regular expressions (if you are exporting GSC data via Data Studio). The core point is that you want to export all pages from GSC that match the problematic page type. That will give you an understanding of any lower-quality pages ranking and driving traffic (that match the page type we are targeting).
Now let’s get more data about landing pages driving traffic from Google organic via Google Analytics.
Google Analytics with Native Regex
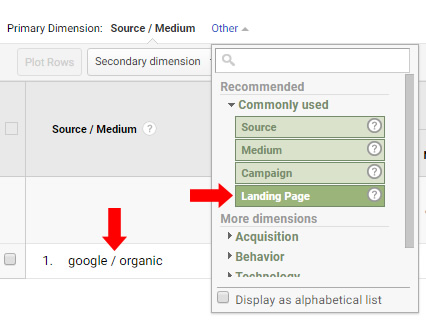
In order to find all problematic page types that are driving traffic from Google organic, fire up GA and head to Acquisition, All Traffic, and then Source/Medium. This will list all traffic sources driving traffic to the site in the timeframe you selected. Choose a timeframe that makes sense based on your specific situation. For this example, we’ll select the past six months.
Then click Google/Organic to view all traffic from Google organic search during the timeframe. Now we need to dimension the report by landing page to view all pages receiving traffic from Google organic. Under Primary Dimension, click Other, then Commonly Used, and then select Landing Page. Boom, you will see all landing pages from Google organic.
But remember, we’re trying to isolate problematic page types. This is where the power of regular expressions comes in handy (as mentioned earlier). Unlike GSC, Google Analytics natively supports regex in the advanced search box, so dust off those regex skills and go to town.
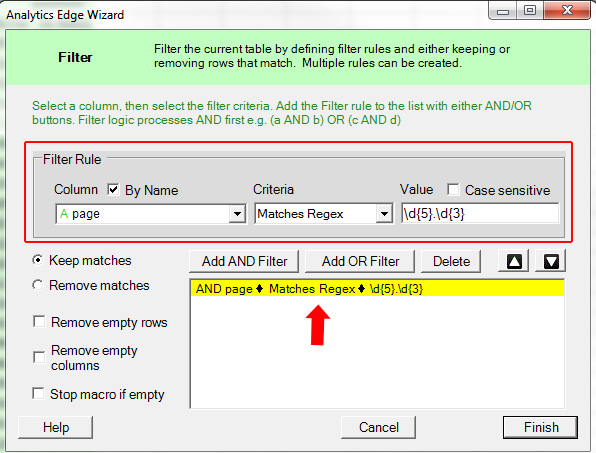
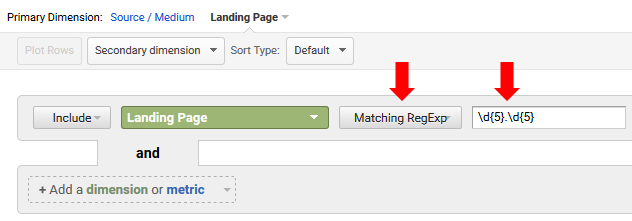
Let’s say all of the problematic page types have two sets of five-digit numbers in the url. They aren’t in a specific directory, but both five-digit sequences do show up in all of the urls for the problematic page type separated by a slash. By entering a regular expression that captures that formula, you can filter your report to return just those pages.
For this example, you could use a regex like:
\d{5}.\d{5}
That will capture any url that contains five digits, any character after that (like a slash), and then five more digits. Now all I need to do is export the urls from GA (or just document the number of urls that were returned). Remember, we’re just trying to estimate how many of those pages are indexed, ranking and/or driving traffic from Google. The benefit of exporting is that you can send them through to your dev team so they can further investigate the urls that are getting indexed by mistake.
Note, you can also use Analytics Edge to bulk export all of your landing pages from Google Analytics (if it’s a large-scale site with tens of thousands (or more) pages in the report. And again, you can combine the Analytics Edge Core Plugin with the GA connector to filter by regex while you are exporting (all in one shot).
Third-party tools like SEMrush
OK, now our case is taking shape. We have the number of pages ranking and driving traffic from Google organic via GSC and GA. Now let’s layer on even more data.
Third-party search visibility tools provide many of the queries and landing pages for each domain that are ranking in Google organic. It’s another great data source for finding pages indexed (since if the pages are ranking, they must be indexed).
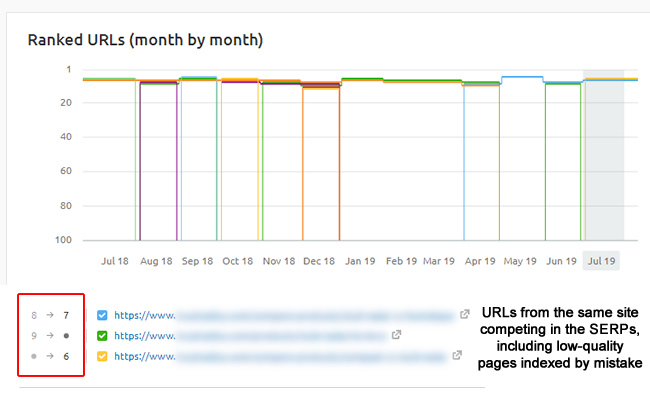
You can also surface problematic pages that are ranking well, which can bolster your case. Imagine a thin and/or lower-quality page ranking at the top of the search results for a query, when another page on your site should be there instead. Examples like this can drive change quickly internally. And you can also see rankings over time to isolate when those pages started ranking, which can be helpful when conveying the situation to your dev team, marketing team, CMO, etc.
For example, here’s a query where several pages from the same site are competing in the SERPs. You would definitely want to know this, especially if some of those urls were lower-quality and shouldn’t be indexed. You can also view the change in position during specific times.
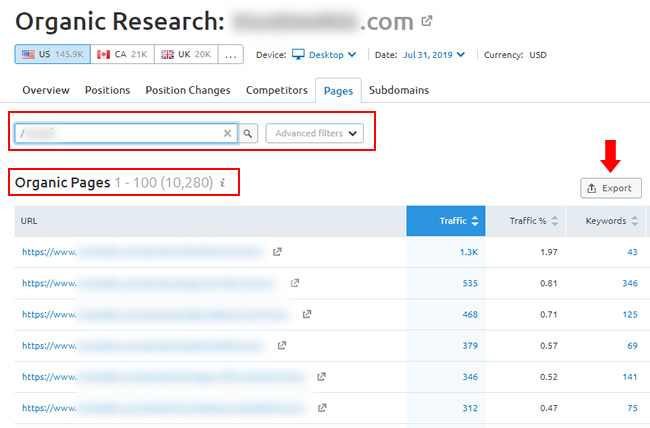
For this example, we’ll use one of my favorite SEO tools, SEMrush. Once you fire up SEMrush, just type in the domain name and head to the Organic Research section. Once there, click the Pages report and you’ll see all of the pages that are ranking in Google from that domain (that SEMrush has picked up).
Note, you can only export a limited set of pages based on your account level unless you purchase a custom report. For example, I can export up to 30K urls per report. That may be sufficient for some sites, while other larger-scale sites might need more data. Regardless, you’ll be gaining additional data to play with including the number of pages ranking in Google for documentation purposes (which is really what we want at this stage).
You can also filter urls directly in SEMrush to cut down the number of pages to export, but you can’t use regex in the tool itself. Once you export the landing pages, you can slice and dice in Excel or other tools to isolate the problematic page type.
Query Recipes – Hunting down rough indexing levels via advanced search operators
OK, now we know the number of pages indexed by understanding how many pages are ranking or receiving traffic from Google. But that doesn’t tell us the number of pages indexed that aren’t ranking or driving traffic. Remember, Google takes every page indexed into account when evaluating quality, so it’s important to understand that number.
Advanced query operators can be powerful for roughly surfacing the number of pages indexed that match certain criteria. Depending on your situation, you can use a number of advanced search query operators together to gauge the number of pages indexed. For example, you can create a “query recipe” that surfaces specific types of pages that are indexed.
It’s important to understand that site commands are not perfectly accurate… so you are just trying to get a rough number of the pages indexed by page type. I’ve found advanced search queries like this very helpful when digging into an indexing problem.
So, you might combine a site command with an inurl command to surface pages with a certain parameter or character sequences that are indexed. Or maybe you combine that with an intitle command to include only pages with a certain word or phrase in the title. And you can even combine all of that with text in quotes if you know a page type contains a heading or text segment in the page content. You can definitely get creative here.
If you repeat this process to surface more urls that match a problematic page type, then you can get a rough number of pages indexed. You can’t export the data, but you can get a rough number to add to your total. Again, you are building a case. You don’t need every bit of data.
Here are some examples of what you can do with advanced query operators:
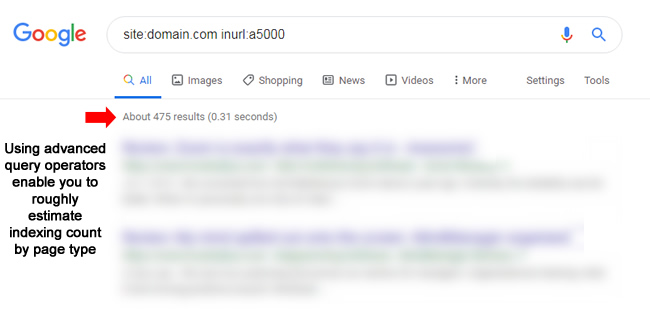
Site command + inurl:
site:domain.com inurl:12/2017
site:domain.com inurl:pid=
Site command + inurl + intitle
site:domain.com inurl:a5000 intitle:archive
site:domain.com inurl:tbio intitle:author
Site command + inurl + intitle + text in quotes
site:domain.com inurl:c700 intitle:archive “celebrity news”
Using advanced query operators enable you to gain a rough estimate of the number of pages. You can jot down the number of pages returned for each query as you run multiple searches. Note, you might need to run several advanced queries to hunt down problematic page types across a site. It can be a bit time-consuming, and you might get flagged by Google a few times (by being put in a “search timeout”), but they can be helpful:
Summary – Using The Data To Build Your Case
We started by surfacing a problematic page type that was supposed to be canonicalized to other pages, but was being indexed instead (since the pages didn’t contain equivalent content). Google just wasn’t taking the hint. So, we decided to hunt down that page type to estimate how many of those urls were indexed to make a case for prioritizing the problem.
Between GSC, GA, SEMrush, and advanced query operators, we can roughly understand the number of pages that are indexed, while also knowing if some are ranking well in Google and driving traffic. In the real-world case I just worked on, we found over 35K pages that were lower-quality and indexed. Now my client is addressing the situation.
By collecting the necessary data (even if some of it is rough), you can tell a compelling story about how a certain page type could be impacting a site quality-wise. Then it’s important to address that situation correctly over the long-term.
I’m sure there are several other ways and tools to help with understanding an indexing problem, but this process has worked well for me (especially when you want to quickly estimate the numbers). So, if you ever run into a similar situation, I hope you find this process helpful. Remember, rel canonical is just a hint… and Google can make its own decisions. And that can lead to some interesting situations SEO-wise. It’s important to keep that in mind.
GG