
It’s always fascinating to see SEO issues that can pop up across large-scale and complex websites. When you are dealing with a large site, technical problems can often scale quickly and yield issues impacting millions, or tens of millions of urls across a site. And some of those technical problems can yield quality problems (if the technical issues impact content and/or UX).
In addition, large-scale sites need to worry about crawl budget, and a technical problem that goes haywire can sometimes heavily impact crawl load. Note, most sites don’t need to worry about crawl budget, but sites with hundreds of thousand of urls, or more, do need to pay attention.
Well, I recently surfaced three different canonical issues across clients that I wanted to share. They were interesting enough that I wanted to document them so other large-scale and complex sites could understand more about how Google handles rel canonical and how that could go off the rails sometimes. I find some site owners aren’t even aware this could happen (or is happening), and they can be late to address the situation. And at a minimum, it’s just smart to know it’s happening so the proper communication can occur within a company. That’s because canonicalization impacts which urls are indexed and ranking. At least that’s the case most of the time… More about that soon.
And I’ll end this post by covering a very interesting finding while researching these case studies (which makes complete sense based on the AI scraping situation we have seen with ChatGPT, Perplexity, and others.) I’ll cover how the urls Google is choosing to index while ignoring the canonical hint from site owners are cascading downstream to ChatGPT and other AI Search platforms. It supports the idea that ChatGPT and others are still scraping Google’s results.
Rel canonical is just a hint and not a directive.
When covering canonicalization with clients, it’s important that everyone involved understands that rel canonical is just a hint. It is not a directive that Google will obey 100% of the time. Google can, and will, make its own decisions and that result may not be what you want or expected. And when urls are canonicalized to other urls, they aren’t indexed and won’t rank in the SERPs. Again, that’s usually the case. There is one interesting situation I have written about in the past that I’ll also cover below. More on that soon.
And like I explained earlier, large-scale and complex sites need to watch canonicalization closely across their page types… If Google goes off the rails for some reason and starts canonicalizing to urls you don’t want it to, then the wrong urls will become the canonical. And those will be the ones indexed and ranking in the SERPs. And that can impact the content users see in the SERPs, the content they visit and consume, etc. And that can impact Navboost data as well, which tracks thirteen months of user interaction signals and can impact rankings. And if you want to learn more about Navboost, you can read my post about ‘highly visible and low quality’ and why that can be problematic.
Here is a good clip from Google’s John Mueller explaining how Google’s systems can ignore rel canonical. And btw, I really miss John’s Search Central hangout videos!:

With that quick introduction out of the way, I wanted to cover some recent interesting examples of Google ignoring rel canonical and making its own decisions. I’ll cover two main cases below and then quickly cover one bonus case with an interesting twist. And then I’ll cover the ChatGPT situation…
Case 1: Rogue subdomain, and Google liked it.
The first case I’ll cover involved a rogue subdomain that my client had no idea was being crawled and indexed by Google. The subdomain was supposed to be behind a login but that functionality was not working correctly. And once that login was failing, Google found the subdomain and started crawling and indexing the content there.
In addition, once Google started crawling the subdomain, it was finding urls similar to urls on the core site. And as you can guess based on the topic of this post, it started choosing the rogue subdomain urls as the canonical urls. And not only were the urls selected as the canonical, but they were ranking prominently in the search results. I first noticed the subdomain in the crawl stats reporting and then requested my client set up that subdomain in GSC to get a closer look… Note, I wrote a post about making sure you know all of your subdomains and checking the crawl stats reporting is one of the things I recommend doing.
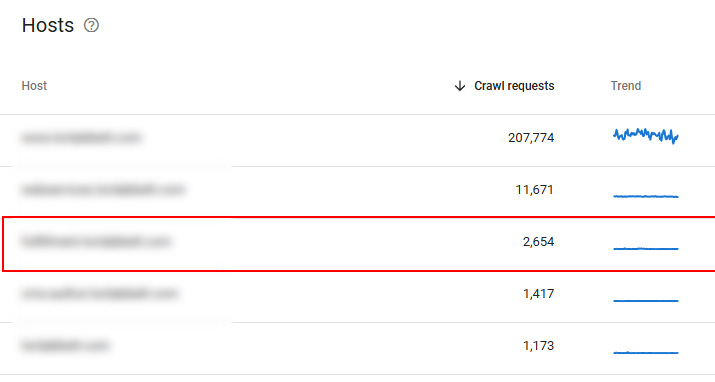
To add insult to injury, the subdomain had the generic globe icon as the favicon, which was terrible from a branding and trust perspective. This is a well-known site and brand, so that just made the situation worse… The site owner thought the subdomain was behind a login, so they didn’t care about the favicon.

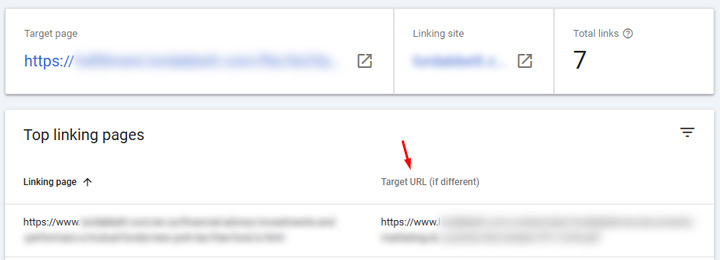
There were also quite a few inbound links pointing to the rogue subdomain in GSC, which I found odd at first. But after digging in, there was some Google trickery on going on. I wrote a post a while ago about how inbound links to canonicalized urls can shift to the canonical url in GSC (a different target). Dan Petrovic also covered that topic, which he called ‘link inversion’. So, when I checked the links in GSC for the rogue subdomain, you could see the target url was different, and it was the url that was now being canonicalized to the url on the rogue subdomain. Like I said earlier, canonicalization problems can spawn other weird issues across a site. This is one of them.
The Removals tool to the rescue, and it’s fast.
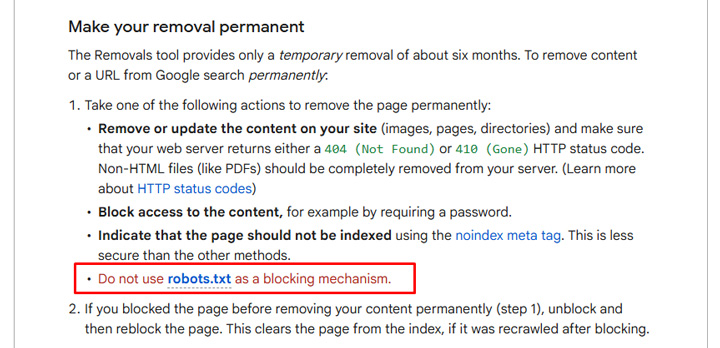
My client wanted that rogue subdomain out of the SERPs, and quickly. Luckily, Google provides the Removals tool in GSC. When used properly, it can be a powerful and fast way to remove urls from the SERPs. Note that I said ‘in the SERPs’ and not index. That’s because the tool does not remove urls from Google’s index. You still need to actually remove the urls via 404 or 410, noindex the urls, or place them behind a login. Also, robots.txt is NOT a solution since Google can still index urls disallowed via robots.txt, but just without crawling the content. Google even explains to NOT use robots.txt in their help documentation for the Removals tool.
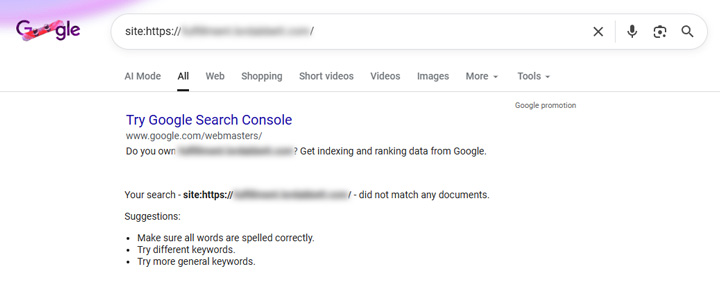
So I removed the subdomain via the Removals tool and waited for it to kick in… That took about 8-10 hours and then the entire subdomain was removed from the SERPs. During that timeframe, my client worked on removing that subdomain from the web (making sure those urls were not accessible anymore). You can see that the subdomain was completely removed from the SERPs below.
Now it will be interesting to see how Google chooses to handle canonicalization across those original urls that were on the core site that ended up getting canonicalized to the rogue subdomain. In other words, how quickly will Google reindex those core urls (and switch canonical urls)? Stay tuned. I’ll post an update with how that goes…
Case 2: Two versions of content, one stronger than the other…
The next case I wanted to cover is a site that contained a page type that provides a unique type of content to the user. The site also provides similar information but on another page of the site that’s linked to from the original page. The initial page is the core page that the site wants indexed with the secondary page there for users if they want to access it. The site owner wanted to make sure the core page was the canonical so it could be indexed and ranking while the secondary page would be canonicalized to the core page (and not indexed and ranking). Again, the core page is the best one from an SEO standpoint.
While digging into the site, I found many examples of Google choosing the wrong page as the canonical. So for queries related to the content, the wrong page was indexed and ranking. And the content and UX are not as strong on that secondary page, so that could be impacting what users consume and their behavior once visiting the site from the SERPs. My client had no idea this was happening and it was impacting tens of thousands of urls on the site.
You could see below that Google was ignoring rel canonical and canonicalizing to the wrong urls.
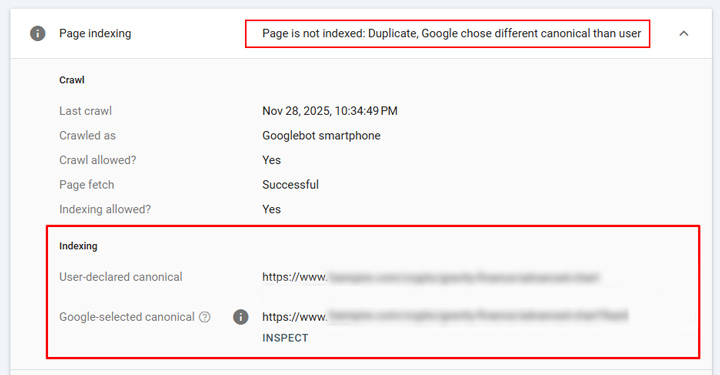
So, Google had the canonicals switched for whatever reason. Seeing this in action and the amount of users going to the wrong urls from the serps, my client started working on cleaning up the situation and making sure the correct urls could be indexed. For example, since the secondary urls are really for users once on the site, and not for Search, noindexing those urls could be a valid approach. Rel canonical alone was not cutting it and my client does not want users seeing those urls in the SERPs or visiting them from the search results. You can see the number is dropping in GSC now, which is great.
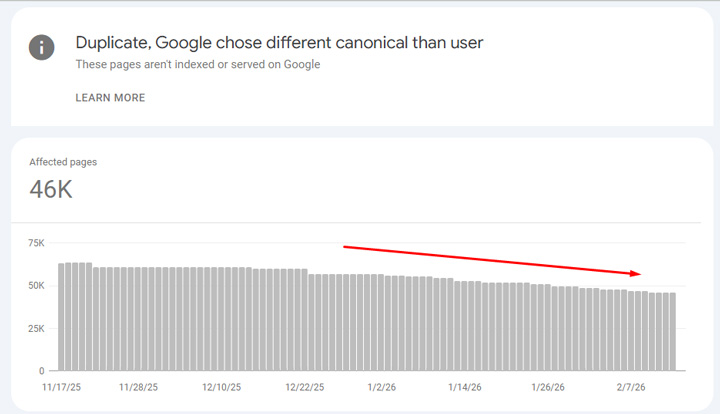
Bonus: Google mass canonicalized urls but the ‘hreflang magic trick’ saves the day.
I mentioned a bonus case study earlier in this post, and it’s a good one. I have a client with a large-scale site (50M+ urls) that uses hreflang targeting two countries, but the content is in the same language. In the past, Google has chosen to index both versions of the urls even though it contained the same content in the same language… until August. Then on one day, Google’s systems chose to canonicalize millions of urls to the other version (all located on the core part of the site directory-wise). I’ll explain how GSC handles canonicalized urls soon from a clicks and impressions standpoint, but this is the drop we saw when checking the directory property (and isolating the country being targeted). Don’t worry, there’s some Google trickery going on there.
And here is an example of a url suddenly being canonicalized to the core url (same language but in the core area of the site):
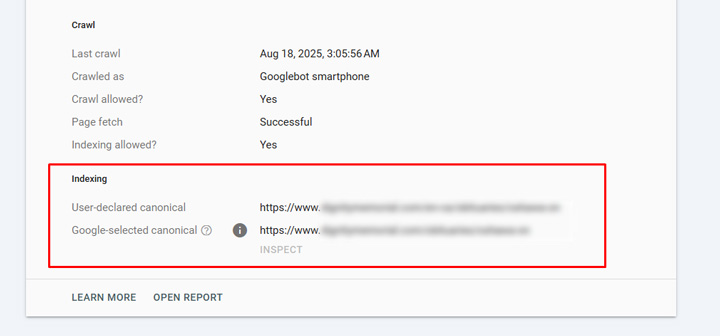
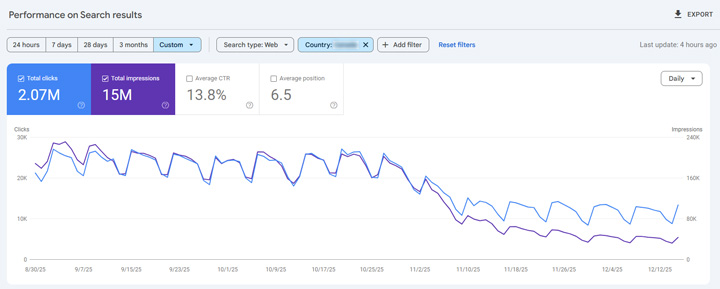
As you can guess, this raised some serious questions as indexing dropped off a cliff for that directory property in GSC and traffic *seemed* to fall for that content. But, Google has a trick up its sleeve for this situation, and it’s something I have covered heavily before. I coined the situation the “hreflang magic trick” and Google confirmed this is how the situation is handled. In other words, this is by design and not some random thing that’s happening across the web. I wrote a two-part case study about the hreflang magic trick if you are interested in learning more about that.
To quickly summarize how the ‘magic trick’ works, Google can canonicalize multiple versions of the same content in the same language to one url. That’s even when the content is targeting different countries. But, and this is where the magic trick comes in, Google can display the correct urls in the SERPs by country, even when those urls are not indexed. That’s because hreflang is set up properly and Google wants to be helpful for users and surface the right content for their country.
And that’s exactly what’s happening with my client. The right urls still show up by country even when Google is canonicalizing those urls to the US English version. Also, traffic looked like it was dropping for that directory only because GSC reports on canonical urls only… So even if the urls are showing up in the SERPs, the impressions and clicks in GSC will go to the canonical urls. That’s a confusing situation, but again, that’s by design in GSC.
Here is where the clicks and impressions went for my client (to the canonical urls). You can clearly see this when isolating performance by country.
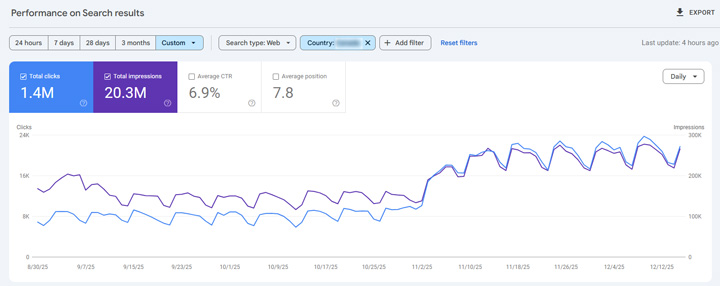
Presto! It’s a magic trick.
Cascading Canonical Problems: A note about scraped Google results and AI Search.
When AI Search platforms leverage Google results, the canonicalization issue can rear its ugly head there as well. For example, if ChatGPT, Perplexity or others are scraping Google’s results and providing that in their own results, then the canonical problems can cascade to the AI Search platforms. It’s just another reason to first understand this is happening and then figure out the best ways to handle the situation.
For example, here is a url surfacing in ChatGPT when it is being canonicalized to another url (and Google is choosing to ignore rel canonical and make its own decision). Isn’t it interesting to see that url surfacing in ChatGPT? Again, ChatGPT seems to be scraping Google still. That’s unless its systems are making the same canonical decision (which I doubt). I have tested a number of urls and I’m seeing similar things in ChatGPT across sites…
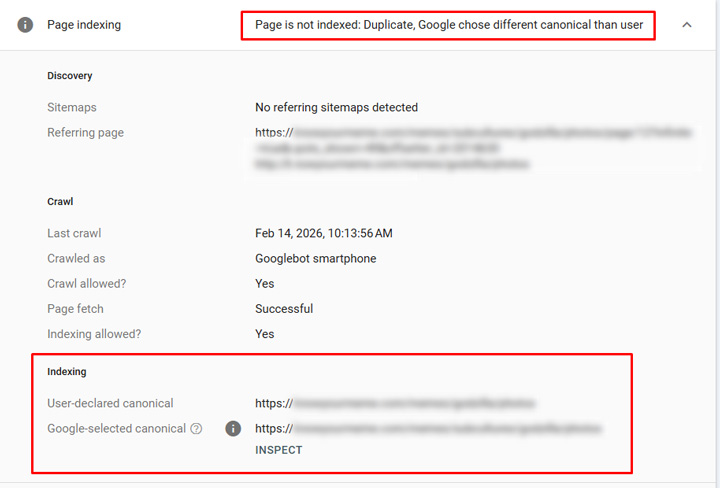
And here is the url in GSC showing that Google is ignoring rel canonical and canonicalizing to the other url (the one ranking in Google AND ChatGPT).
Again, I have tested this with a number of urls across sites where Google is ignoring rel canonical and choosing another url instead. This could be another smoking gun revealing that ChatGPT is scraping Google results…
Summary: Rel canonical is a hint and Google can ignore your recommendation.
If you run a large-scale and complex site, it’s incredibly important to keep an eye on how Google is handling canonicalization across your urls. Rel canonical is just a hint and Google can, and will, ignore your recommendation and make its own decisions. And on a large-scale site, that can yield many urls being indexed that maybe shouldn’t be… And of course, those urls will rank in the SERPs and drive users to the wrong versions of the content.
Also, as I covered at the end of this post, ChatGPT and other AI Search platforms scraping Google’s results could be showing the incorrect canonical as well. So the problem can cascade to AI Search platforms as well…
I hope these case studies helped you understand more about how this can happen and how to handle those situations. One thing is for sure, canonicalization can be a fluid situation. I recommend staying on top of it the best you can.
GG