
On January 11, 2021 Google announced improvements to GSC’s Index Coverage data. With the update, which is clearly apparent in the reporting, Search Console removed the generic “crawl anomaly” issue (and mapped those to more granular issues), changed how urls are reported that are blocked by robots.txt, added a new issue called “indexed without content” as a warning, and then had one final note about soft 404s. That last bullet said, “Soft 404 reporting is now more accurate.” And based on my work with large-scale sites, I was particularly interested in that final bullet.
A number of the sites I help had tens of thousands, or even hundreds of thousands of soft 404s being reported based on the nature of their content. Starting on January 5, 2021, the number of soft 404s reported in GSC fell off a cliff. I’m talking about a severe drop, like these examples:
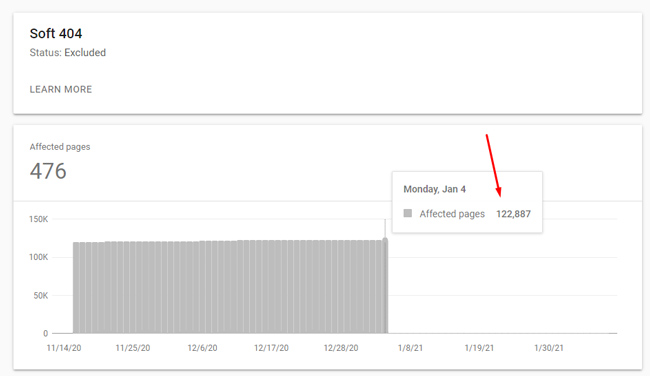
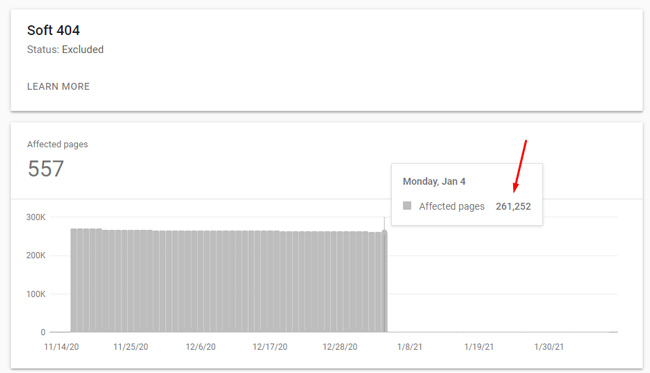
In order to understand why alarms were going off in my office, and why I’m particularly interested in those drops, let me quickly cover more about soft 404s. Then I’ll explain what I found once I dug into each situation.
A Deeper Look at Soft 404s:
Google explains that a soft 404 is a url that tells the user the page doesn’t exist, but it still returns a 200 header response code (instead of a hard 404). In practice, the soft 404s that Google has surfaced historically have been urls that span different page types. For example, the most obvious is a product that’s no longer available that still returns a 200 response code. It might have very little content and a message telling users the product is not available on the site anymore.
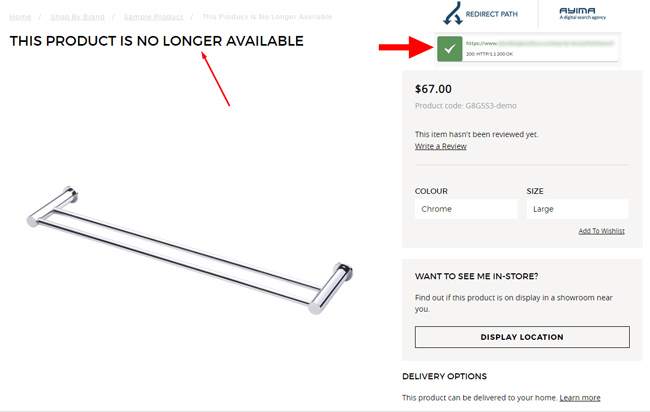
But, other types of pages have showed up in the soft 404s reporting over time. For example, I’ve seen super-thin pages show up there like articles, slideshows, job listings, pages with images or video with little textual content, and more. And on larger-scale sites, those pages can be problematic quality-wise depending on how Google is handling them.
For example, a soft 404 is treated as a hard 404. Google will not index those urls identified as soft 404s. But, if a site had a big soft 404 problem, I often found that Google wasn’t always handling all of those pages types as soft 404s… And that led to many thinner urls getting indexed.
So, if you had 50K super-thin pages and Google saw them as soft 404s, then technically that shouldn’t be a huge problem quality-wise. Since they are seen as hard 404s, Google will obviously not take them into account when evaluating quality.
But, what if suddenly those urls aren’t seen as soft 404s anymore? Well, those urls could be counted when Google evaluates quality overall for the site. That’s a big reason my “quality antennae” went up when I saw tens of thousands, or even hundreds of thousands, of soft 404s suddenly disappear. Are they indexed now, categorized as another issue in GSC and not being indexed, or maybe not even known to Google anymore? I NEEDED TO KNOW!
In addition, soft 404s can impact crawl budget, which can be a concern for larger-scale sites. Note, most sites do not need to worry about crawl budget. Only very large sites (typically sites with over one million urls) need to worry about crawl budget. For example, this site needs to worry about crawl budget:
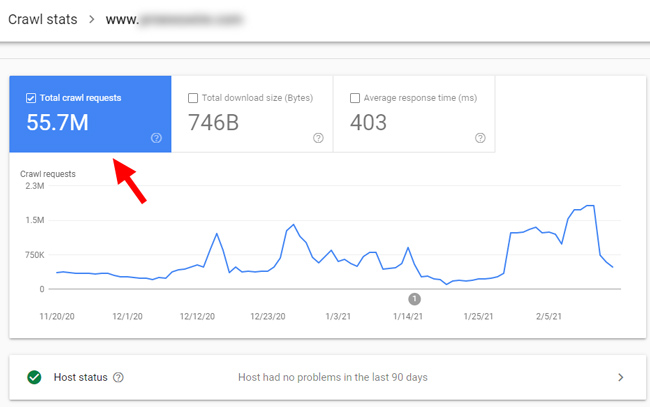
Google’s own documentation explains that soft 404s can eat up crawl budget. So it’s another concern when it comes to soft 404s (and understanding where they magically went on 1/5/21). In the past, if you saw them flagged in GSC, then you could identify patterns and handle appropriately. But if they suddenly disappear, it could be harder to surface and handle.
In Search Of: Lost Soft 404s
This all leads me back to one question… where did all of those soft 404s go?? After seeing the number of soft 404s drop off a cliff on 1/5/21, I decided to dig into the data across sites and find out what happened. So, I grabbed my virtual pickaxe and headed into the GSC mine. I was determined to find out how those urls were being treated now.
Now, if you choose to dig into search console after a change is rolled out by the GSC product team, you’ll quickly realize that you cannot access historical data. That sucks and means you will have a hard time finding urls previously categorized as soft 404s unless you documented them somehow. I had this covered since I always dig heavily into GSC data when auditing client sites. I was able to open my vault of recent audit documents and resurface many soft 404s that were reported over the past six to twelve months.
Based on digging into the data, I was sometimes relieved with what I discovered for certain situations, but also alarmed by what I found in other situations. I’ll explain more below.
Where Did Soft 404s Go and How Is Google Currently Handling Those URLs?
Below, I’ll cover the various categories of findings based on digging into a number of large-scale sites that previously reported many soft 404s. On 1/5/21, the number of soft 404s dropped off a cliff and I was determined to find out how they were currently being treated.
Super-interesting: “The URL is unknown to Google”
This was incredibly interesting to me. I noticed many url across sites that were once reported as soft 404s now returning “The URL is unknown to Google” when inspected in GSC. It’s almost like Google completely wiped out the history for these urls.
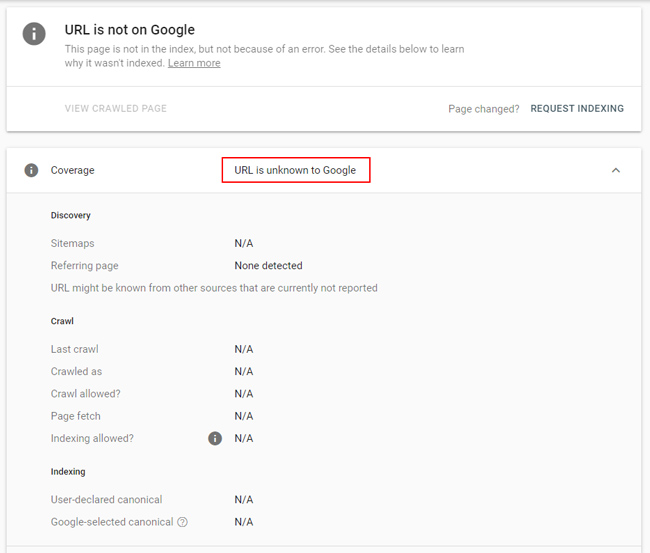
This isn’t a category that shows up in the Coverage reporting for obvious reasons… since it’s NOT known to Google. But, it was known to Google at some point recently. I know that for sure. Google’s documentation does explain more about this categorization, but I’m not sure it answers why the soft 404s are now “unknown to Google”. Here is what Google’s documentation explains:
“If the index coverage status “URL is unknown to Google” appears, it means that Google hasn’t indexed the URL either because it hasn’t seen the URL before, or because it has found it as a properly marked alternate page, but it can’t be crawled.”
I’m going to reach out to Google to learn more about this. I would imagine that Google handling many urls as this category is helping it improve the efficiency of its own systems, but again, I’ll see if Google can comment about this. But if it’s unknown to Google, it won’t hurt your site quality-wise. That’s good.
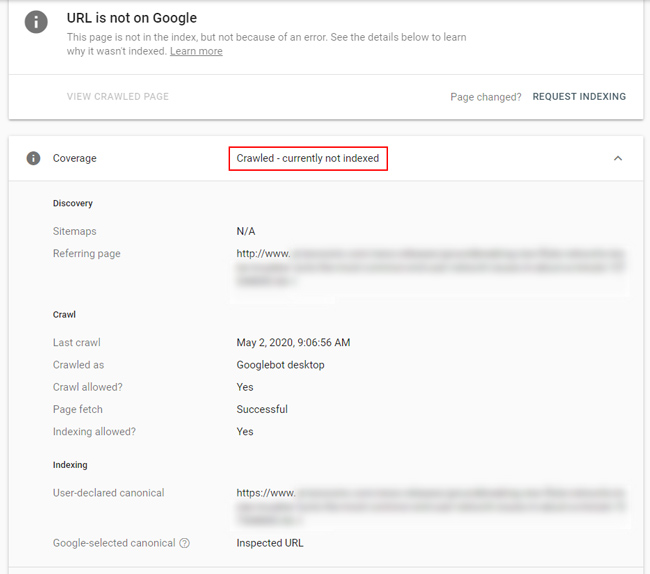
“Crawled, not indexed” and “Discovered, not indexed”:
I have covered this category a number of times in my other posts about technical SEO and broad core updates. Both “Crawled, not indexed” and “Discovered, not indexed” can signal quality problems and/or crawl budget issues. With “Crawled, not indexed”, Google discovered and crawled the url, but has chosen to not index it. I have often found low-quality or thin content when analyzing this category across sites (or just parts of a site Google isn’t digging for some reason).
So, if your soft 404s end up as “Crawled, not indexed”, then that’s ok in the short-term (since they aren’t being indexed and can’t be held against the site quality-wise), but I would still heavily dig into the urls and handle them appropriately. This is also one of the reasons I believe we need larger exports from GSC’s Coverage reporting! Exporting this category in bulk would help site owners identify more patterns across the site that could be causing problems.
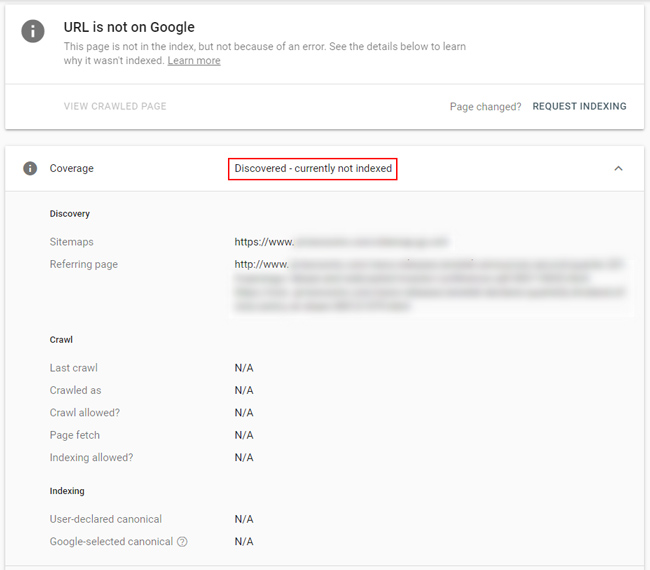
And for “Discovered, not indexed”, Google knows about the url, but has decided to not even crawl it (and clearly not index it). I have seen quality problems and problematic url patterns while analyzing this category of urls. For example, with some large and complex sites with deep quality issues, it’s like Google knows ahead of time what it’s going to find on many of those urls (based on url structure) and doesn’t even want to crawl them.
So, if you see many soft 404s now being categorized as “Discovered, not indexed”, then that’s also ok in the short-term since they can’t be held against the site quality-wise if they aren’t being indexed. But just like with “Crawled, not indexed”, I would dig in and make sure the urls are being handled properly. If they should 404, then make sure they return hard 404s. If they are thin and low-quality, then boost the content there. And if it’s a problematic area of the site, then work on improving that area overall. Remember, “Discovered, not indexed” means Google knows about the urls, but doesn’t believe it’s worth it to even crawl them (let alone index them).
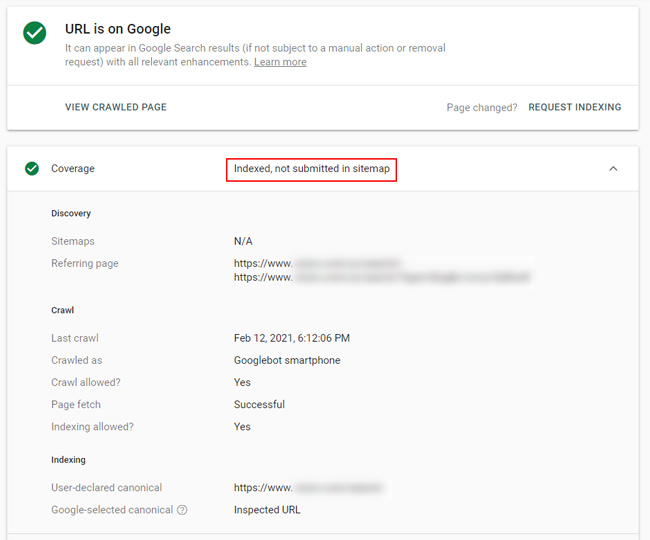
URLs Now Indexed: Danger Will Robinson! Danger!
Yes, this is a super important category. When digging into urls that were previously categorized as soft 404s, I noticed some of them were now being indexed! That can be a dangerous situation for some sites. For example, if they were thin and low-quality urls that Google is now indexing for some reason, those urls will now be taken into account while Google evaluates quality for the site overall. “Quality indexing” is very important (especially for larger-scale sites), so having an influx of low-quality content get indexed is not a good thing.
If you notice many urls that were once flagged as soft 404s now being indexed, then it’s important to handle those urls appropriately now. For example, you can noindex low-quality content, boost the content there (improve it so it meets or exceeds user expectations), 301 it to a newer version of the content, or 404 the pages if they shouldn’t be on the site anymore. But I would not leave them as-is if they are low-quality or thin.
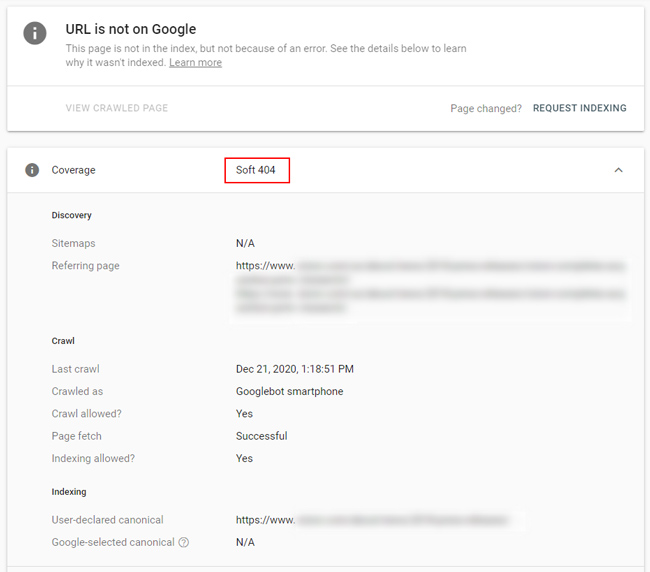
True soft 404s still seen as soft 404s:
Even though many soft 404s disappeared from the reporting in GSC, there were still urls categorized as true soft 404s. For example, pages that were literally blank that returned 200 header response codes, pages that returned “not found” messages on the page, but returned 200 response codes, etc. Again, true soft 404s. I guess this is the “handling soft 404s more accurately” part from Google. For these urls, I would make sure to handle them appropriately. If they should 404, then have them return hard 404s and not 200 header response codes. And if they shouldn’t be seen as soft 404s, then fix or boost the content there.
Moving Forward: What Site Owners Can Do
If you have seen a big drop in soft 404s starting in early January 2021, then I highly recommend digging into the situation. If you don’t have historical data containing urls that were once categorized as soft 404s, there’s not really much you can do to see how those soft 404s are being reported now. But, if you did document soft 404s for your site, then you can inspect those urls to see how Google is handling them now.
Are they “Unknown to Google” now, are they being categorized as “Crawled, not indexed”, “Discovered, not indexed”, are they still soft 404s, or are they being indexed? And if they are being indexed, then they can be counted when Google evaluates quality for the site overall. That’s why it’s important to handle the urls appropriately.
Summary – Know Your Soft 404s
With the latest data improvements in GSC, Google started better handling soft 404s. That’s great, but many sites saw a big drop in urls reported as soft 404s at that time. Since that category in GSC often yielded thin or low-quality content on a site, it’s important to understand how Google is currently handling the urls. Are they still not being indexed, or are they now being indexed and counting towards quality? I recommend digging into the situation for your site and then handling those urls appropriately.
GG