
I’ve written in the past about how a robots.txt file could look fine, but actually not be fine. For example, maybe you add your directives, a sitemap file or sitemap index file, and then upload it to your site. You think all is good, but you find that directives are not being adhered to, maybe a boatload of urls that are being crawled that shouldn’t be, etc. When that happens, it can have a big impact on SEO (especially on large-scale sites with many urls that should never be crawled).
So why does this sinister robots.txt problem happen? It often comes to down a single character. Literally. Sure, it’s an invisible character, but a character nonetheless. It’s called the UTF-8 BOM and I’m going to explain more about that in this post. Unfortunately, I’ve come across this issue many times during audits and while helping companies with technical SEO. It’s sinister, since it’s invisible. But the results are extremely visible (and can be alarming).
Below, I’ll cover what UTF-8 BOM is, how it can impact your robots.txt file, how to check for it, and then how to fix the problem. So, if your robots.txt file is bombing, and you are still scratching your head wondering what’s going on, then this post is for you.
What is UTF-8 BOM?
BOM stands for byte order mark and it’s used to indicate the byte order for a text stream. It’s an invisible character that’s located at the start of a file (and it’s essentially meaningless from an SEO perspective). Some programs will add the BOM to a text file, which again, can remain invisible to the person creating the text file. And the BOM can cause serious problems when Google tries to read the file. Actually, the UTF-8 BOM can make your robots.txt file, well, bomb… Sorry for the play on words here, but I couldn’t resist. :)
What can happen to a robots.txt file when UTF-8 BOM is present?
As mentioned above, when your robots.txt file contains the UTF-8 BOM, Google can choke on the file. And that means the first line (often user-agent), will be ignored. And when there’s no user-agent, all the other lines will return as errors (all of your directives). And when they are seen as errors, Google will ignore them. And if you’re trying to disallow key areas of your site, then that could end up as a huge SEO problem.
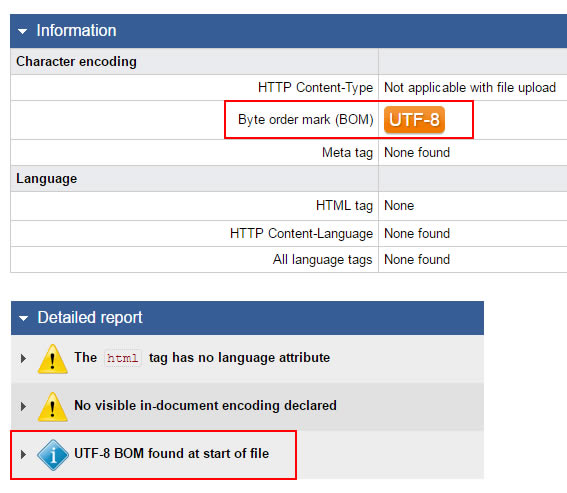
For example, here’s what a robots.txt file looks like in GSC when it contains UTF-8 BOM:
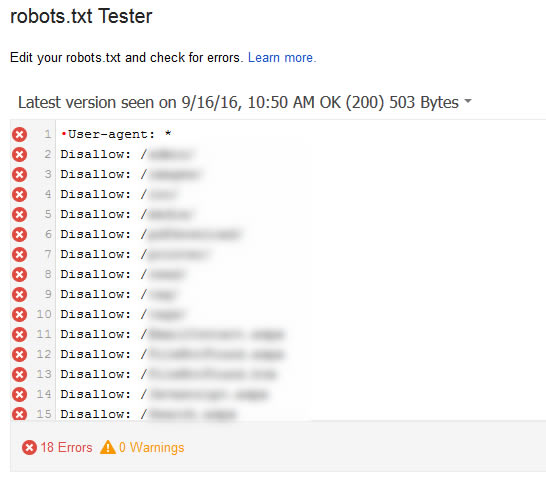
Needless to say, all of the directories that should be disallowed are not being disallowed. And that means many urls that shouldn’t be crawled are being crawled (and many are being indexed). This can lead to all sorts of nasty SEO problems. And that could include quality problems, as well, depending on what is being crawled and indexed.
How to identify UTF-8 BOM:
Right now, you might be sweating a little. Maybe you’ve seen problems with your robots.txt file and subsequent indexation, and you’re now wondering if UTF-8 BOM is the problem. Don’t worry, I’ll quickly walk you through how to check your robots.txt file now.
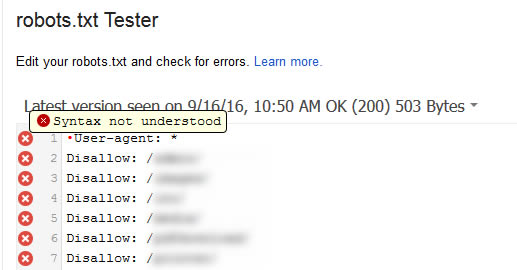
1. First, fire up GSC and use the robots.txt Tester. When you view the report, does it look like the screenshot above? Is the first line showing a red X next to it? If so, hover over the x and you might see a hint that says, “Syntax not understood”. If so, there’s a good chance you’ve got the UTF-8 BOM situation I’ve been explaining.
2. Next, visit the W3C Internalization Checker. This tool will enable you to upload your robots.txt file and check for the presence of UTF-8 BOM.
3. Next, click the tab labeled “By File Upload”:
4. Next, click “Choose File” and select your robots.txt file. Then click the “Check” button:
The tool will return the results, which will include a line about UTF-8 BOM. If you see that in the results, you know what the problem is (which is great). That’s the smoking gun.
How to fix UTF-8 BOM in your robots.txt file:
Fixing the issue is pretty easy. I recommend using a text editor like Textpad to create your new robots.txt file. When saving the file, ensure that BOM is not selected (some text editor programs have an option for adding the BOM).

Also, make sure you’re not using a word processing application like Microsoft Word for creating your robots.txt file. I’ve seen that cause problems too. You should be using a pure text editor for creating your robots.txt file, .htaccess file, xml sitemaps, etc. I’m a big Textpad fan, but there are many others you can use as well.
Once you make the changes, then use the W3C internationalization tool to check the revised file. If the BOM doesn’t show up, you’re good to go. If it is, you are doing something wrong while creating the robots.txt file. Go back and start over using a pure text editor.
After you’ve fixed the problem, head back to GSC and to the robots.txt Tester. The tool enables you to submit a request to Google to retrieve your latest robots.txt file (after you upload the new one).
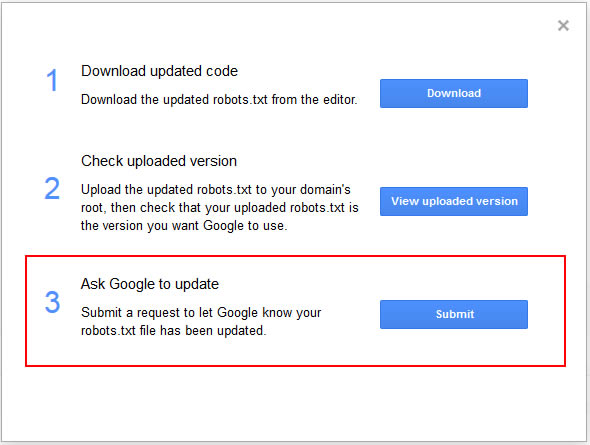
If you’ve done everything correctly, the errors should be removed from the robots.txt Tester and your directives will now work (blocking directories and files that should not be crawled).
Side note: Blocking does not mean “remove from index” (usually):
If you’ve been experiencing robots.txt issues due to the UTF-8 BOM problem I’ve covered here, your work might not be done. If many pages have been indexed, then just blocking via robots.txt will not remove those pages from the index. Over time, Google can remove them, but I would try and get those undesirable urls out of Google’s index quickly.
For example, you could add the meta robots tag using “noindex” and submit an xml sitemap to Google that contains all of the urls that you want deindexed. Then once you’re sure those urls are deindexed, you could block those directories again via robots.txt. But remember, if you add noindex to files that are being blocked via robots.txt, then Google will never be able to see the meta robots tag… You will need to let Google recrawl those pages first, see the meta robots tag using noindex, and then you can start blocking the files again. That’s a confusing subject for many in SEO, but it’s a really important one.
Summary – Don’t Let UTF-8 BOM Turn Into An SEO Bomb
There are several hidden and sinister problems that can rear their ugly heads in SEO. The UTF-8 BOM is one of them. If your robots.txt file is not working as expected, throwing errors, and causing serious headaches, then follow the instructions in this post to test for UTF-8 BOM. You might find that a hidden character is the gremlin causing major SEO problems. Then it’s up to you to remove that problem by “disarming the BOM”. :)
GG
Useful to know. Cheers guys!
Hey, glad you found my post useful. The invisible character issue caused by UTF-8 BOM can be a nasty one. SEOs need to “Disarm the BOM”. :)
I wonder if this applies to disavow files as well…
Great question. John mentioned that errors in sitemaps and disavow files get flagged in the GSC UI, so webmasters will at least know there’s an issue. The problem with robots.txt is that it can look fine to the naked eye, but could have problems.
Glenn,
I’ve had this issue repeatedly. You tell the clients about it, they fix it and the next time an admin updates the robots.txt file and the BOM appears again. When the responsible party has his/her text editor automatically insert the BOM byte, it can get annoying.
A precautionary measure is to start the robots.txt file with a comment.
Right, it can be an annoying and problematic situation (especially on large-scale sites where many urls can be crawled and indexed by accident). And that’s a great point about adding a comment (or empty line). Then if the BOM is inserted by accident, only that line will be ignored. Thanks Hristo!
Yes, a very common situation (and as Hristo pointed out, a first-line comment is the easiest fix).
A bit of background history: since UTF-8 was designed to be fully background compatible with ASCII, a valid UTF-8 file per-se couldn’t be distinguished efficiently from an ASCII file. That’s why MS – but we should not blame them this time – decided to add a header to mark the common Unicode formats in case no HTTP header were available (e.g. in case of file served from a local file system). To do that they resorted to BOM characters, there are five possible values (UTF-8, UTF-16, UTF-16be, UTF-32, UTF-32be), conceived not to break any Unicode specification. Unfortunately the *nix world never caught up updating some basic libraries which shouldn’t have been affected in the first place were they fully compliant to the original Unicode specifications.
I wish Google were smarter detecting it, as a BOM is a perfectly fine header for a Unicode file, very common, and extremely easy to detect and handle for a programmer.
BOM byte’s presence can be easy visually located: open the robots.txt in your browser and set encoding to iso 8859-1. BOM byte, if present, will be visible on the beginning of the document as . To get rid of it just save the content of robots.txt in any advanced code editor, like notepad++, with the saving option “utf-8 without BOM byte”. This issue makes much troubles to many webmasters on the beginning of their career: every configuration file of any CMS, like Joomla, WordPress and the like has interpretation problem, if BOM byte exists.
It’s the ones you don’t see that get you.
Isn’t that the truth? :)
Slick trick – I suspect there a a few out there who used Word to create robots.txt and this article will save them :-)