
{Update: Google’s John Mueller replied to my question on Twitter about this situation. You can read John’s feedback here.}
{Update 10/27/18: My client’s dev team figured out the problem and I provided more information about that below.}
I’ve been helping a client with a large-scale CMS migration recently and came across a very interesting, and potentially scary, situation. It’s a large and complex site with many moving parts, so there is a lot to process (both figuratively and literally).
The site has over one million pages indexed, and many more that get crawled based on the proper use of noindex in certain areas of the site. That was a big change for the site when I first started helping them a few years ago (after they got pummeled by a major algorithm update). Therefore, I’m always making sure those areas of the site are handled properly (as changes and updates go live on the site).
And now that a CMS migration was under way, I made sure to check on those areas of the site to make sure all was ok. It ends up they were ok… but they sort of weren’t either. Confused? Then read on.
The Magic Show Begins – Typical checks after a CMS migration
As I started crawling and checking the site after the migration went live, I noticed something very strange. The number of noindexed pages during my crawls was sometimes lower than what I expected. And while manually checking those pages, I noticed that my trusty AYIMA plugin sometimes went red (indicating the page was not indexable), but sometimes it didn’t. I found that odd and began to dig in further. Note, other plugins like the DeepCrawl indexability plugin also showed those urls were indexable. Again, strange…
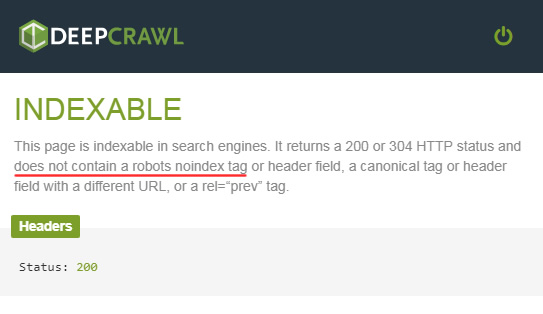
Static HTML Correct, Rendered HTML Not So Much…
When checking the areas of the site I mentioned earlier, and digging into the source code (the static html), I noticed that the meta robots tag was in the proper place and contained the correct directives. For example, it was placed in the head of the document and contained “noindex, follow”.
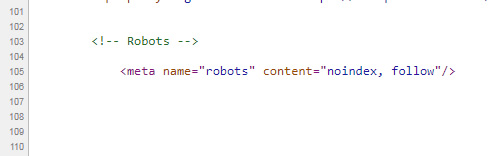
But we know that Google renders the page and that rendered html can be different than the static html. For example, JavaScript-based content will be rendered and can be indexed by Google. So, I started to check the rendered html via a number of tools like Google’s mobile-friendly test, the rich results testing tool, Chrome Dev Tools (using inspect element), and then various crawling tools like DeepCrawl, Screaming Frog, and Sitebulb. They have the ability to render the page, revealing what the final rendered html would reveal.
Note, the rich results testing tool will render the page via Googlebot desktop, while the mobile-friendly testing tool will render the page as Googlebot for Smartphones. Chrome Dev Tools will show you the rendered html via “inspect element” and then crawling tools like Screaming Frog, Sitebulb, and DeepCrawl have options for crawling with JavaScript rendering on. Therefore, it’s good to test across all of the tools to see what the results are across both mobile and desktop.
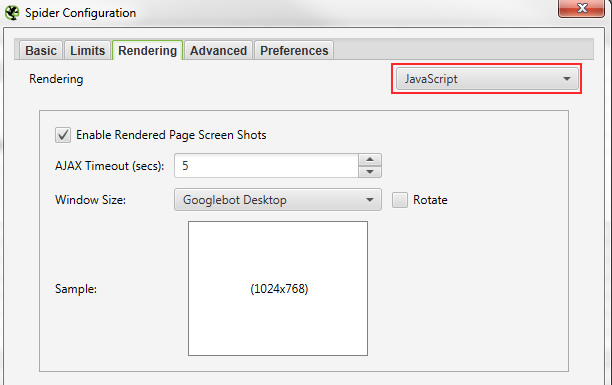
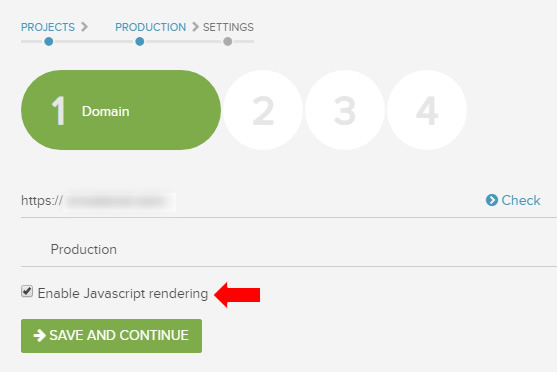
Render JavaScript option in Screaming Frog (first image) and then DeepCrawl (second image):
Wait, what just happened?
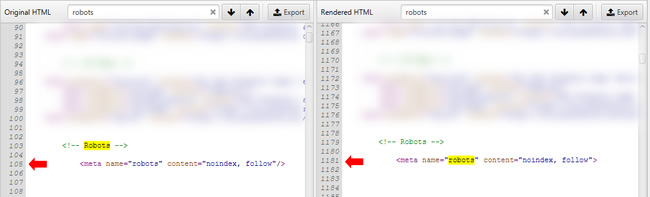
When I checked the rendered html across those tools, I witnessed the magically moving meta robots tag. The robots tag, and some other head elements, were now in the body of the document and not the head. I had to double and triple check this to make sure I was seeing it properly.

The meta robots tag went from line 105 in the source code to line 1,181 in the rendered version of the code. And again, it was NOT in the head of the document, where it needs to reside. It was now in the body! Here is a screenshot from Screaming Frog showing both the source html and the rendered html. Notice the line numbers next to each meta robots tag:
But Is It Safe?
When spot-checking urls containing the magically moving meta robots tag, they indeed were noindexed. Therefore, I’m assuming Google is using the meta robots tag from the static html and not in the rendered html (more about this in the next section). But will that always be the case? Again, on a site with millions of noindexed pages, and a history of getting hit by major algorithm updates, is it safe to believe that the magically moving meta robots tag won’t eventually cause problems? All good questions.
Google’s 2-phase approach for indexing JavaScript-based content
I passed all of this information along to my client and that was sent to the dev team. I’m still waiting to hear back about why this is happening, but needless to say, it could be very dangerous on a large-scale site with many moving parts. In addition, this is happening in sections of the site that absolutely should be noindexed and not released into the SEO wild.
Also, Google has explained that it uses a two-phase approach for indexing JavaScript-based content. The first phase will crawl and index the static html. And the second phase, which can take a few days or longer, will process and index the rendered html. And remember, the rendered html is where the meta robots tag ends up in the body of the document (for this case).
Here is John Mueller explaining that inserting canonical tags or meta robots tags via JavaScript can cause issues based on the initial phase of indexing versus the second phase (where it renders and indexes the JavaScript version):

So, theoretically for my client, Google would first see and process the proper meta robots tag in the static html, but then it would process and index the rendered html, which has the meta robots tag in the body of the document. If that’s the case, then Google may not decide to noindex the page in the long-term. I have to dig in further across those areas of the site to see how many pages are being noindexed versus indexed over the long-term (even though I’m hoping we just fix this problem sooner than later so we don’t need to worry about this!)
Again, with millions of pages currently being noindexed, I would NOT want to see a chunk of those pages suddenly get indexed. Remember, this site has felt the wrath of major Google algorithm updates in the past. It’s doing very well now, but the battle scars remain.
The CMS or the implementation?
Since my client just moved to a new CMS (a popular enterprise CMS), I naturally starting wondering if the problem was CMS-based or if it was due to the implementation of the CMS. Companies typically tailor the CMS implementation with various customized elements and code, and that can always cause unforeseen issues.
So, I decided to check several others sites running the CMS and they looked fine. The meta robots tag was on the same line in the html in the static and rendered versions (and it was located in the head of the document). Therefore, this looks to be an implementation problem. That’s often the case with CMS migrations. It’s not necessarily the CMS, it’s more about how the implementation goes. That’s where bugs can creep in and potentially cause big problems SEO-wise.
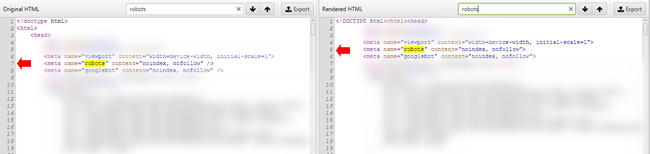
Update: Feedback From Google’s John Mueller
John Mueller replied to my question about this situation today on Twitter. John explained that if the meta robots tag is in the right place in the static html, then that should be fine. He explained that it’s different when you need to do something specific after indexing and rendering (like adding hreflang via JavaScript). That’s great to know. I am still going to make sure the problem is fixed, since I’m not a fan of having magically moving meta robots tags, but it’s great to know this shouldn’t be a big problem. That makes sense, since I am seeing those pages accurately noindexed. Here’s John’s tweet:
Update: The problem was identified and a fix was implemented
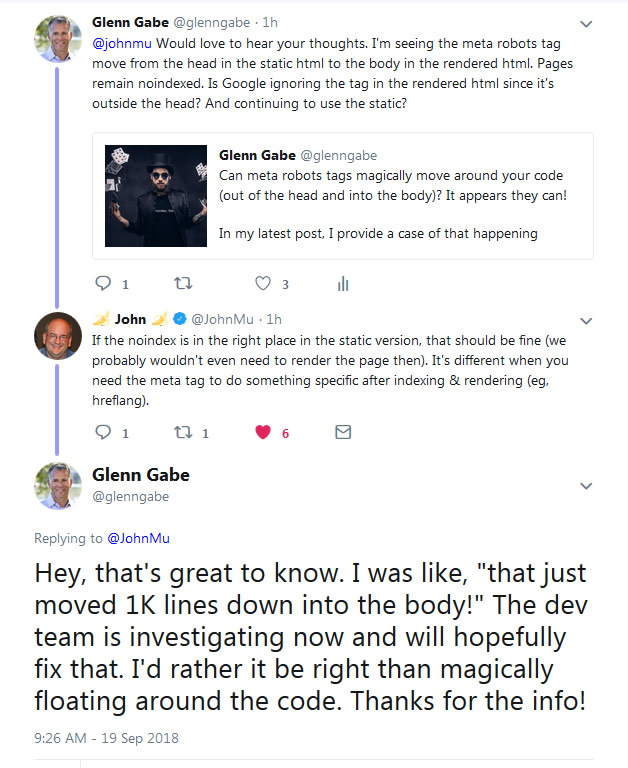
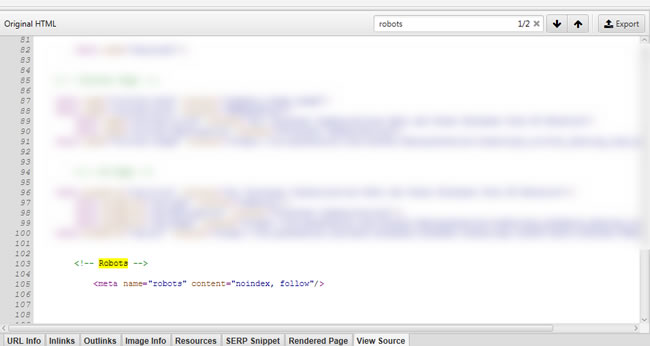
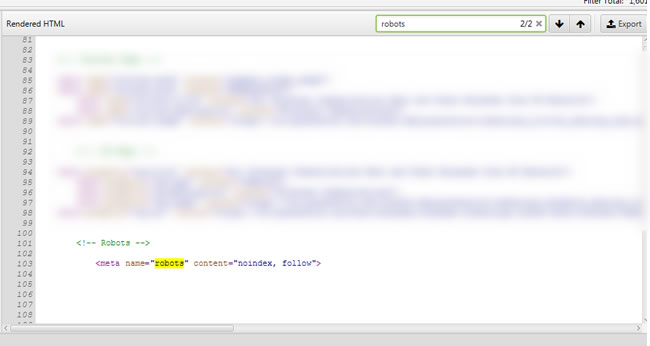
Well, my client’s dev team finally figure out the problem, which is great! It ends up there was a conflict with a GDPR script where it was validating which code to execute (production versus staging). And sometimes the validation was failing, or just late to determine the logic that was necessary (which resulted in a conflict with other JavaScript code on the page). The fix was implemented and the meta robots tag is now correctly being published in the head of the document for both the static and rendered version of the html. See the screenshot below after crawling the pages with rendering on.
Static HTML:
Rendered HTML:
Quick Tips For Stopping Magically Moving Meta Robots Tags
Based on this case, I have some closing tips for SEOs and site owners that are going through a CMS migration (or for anyone that wants to make sure the meta robots tag, rel canonical, or other important SEO code is set up correctly).
- Test your site via multiple tools that enable you to view the rendered html. That includes the mobile-friendly test (mobile), the rich results testing tool (desktop), Chrome Dev Tools (using inspect element), etc.
- You can also test your site via multiple crawling tools that render JavaScript, including Screaming Frog, DeepCrawl, and Sitebulb. Then check the static html versus the rendered html. And make sure to check important reports to see what has changed compared to previous static crawls. For example, you might see noindexed pages drop off a cliff when you compare a static crawl to a JavaScript-rendered crawl. If so, why?
- If it’s a third-party CMS (and not custom built by your company), then test other sites running the CMS. You might see consistent behavior across those others sites, which would signal a problem with the CMS itself. But if they look fine, then it’s probably your implementation of the CMS. That’s important to know.
Summary – For SEO, don’t rely on magically moving code
This was an interesting case for sure. Any time you see important directives magically moving around the html code, you definitely want to dig in and find out what’s going on. And then it’s important to quickly address the situation with the dev team. That’s especially the case for large-scale sites with many moving parts. I’ll try and post an update after my client surfaces the problem and applies a fix. Needless to say, I’m hoping the magic show ends soon. :)
GG