
Updated: April 2022
The post now contains the most current tools I use for checking the x-robots tag for noindex directives. The list includes tools directly from Google, Chrome extensions, and third-party crawling tools.
——
I have previously written about the power (and danger) of the meta robots tag. It’s one line of code that can keep lower quality pages from being indexed, while also telling the engines to not follow any links on the page (i.e. don’t pass any link signals through to the destination page).
That’s helpful when needed, but the meta robots tag can also destroy your SEO if used improperly. For example, if you mistakenly add the meta robots tag to pages using noindex. If that happens, and if it’s widespread, your pages can start dropping from Google’s index. And when that happens, you can lose rankings for those pages and subsequent traffic. In a worst-case scenario, your organic search traffic can plummet in an almost Panda-like fashion. In other words, it can drop off a cliff.
And before you laugh-off that scenario, I can tell you that I’ve seen that happen to companies a number of times during my career. It could be human error, CMS problems, reverting back to an older version of the site, etc. That’s why it’s extremely important to check for the presence of the meta robots tag to ensure the right directives are being used.
But here’s the rub. That’s not the only way to issue noindex, nofollow directives. In addition to the meta robots tag, you can also use the x-robots-tag in the header response. By using this approach, you don’t need a meta tag added to each url, and instead, you can supply directives via the server response.
Here are two examples of the x-robots-tag in action:
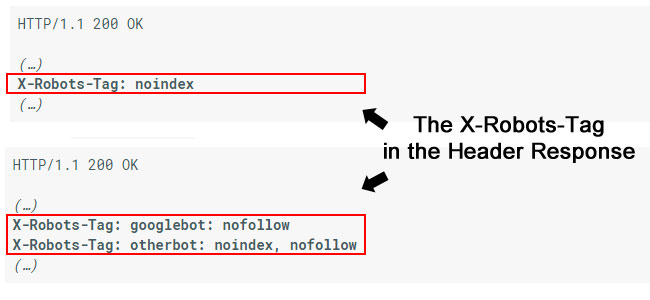
Again, those directives are not contained in the html code. They are in the header response, which is invisible to the naked eye. You need to specifically check the header response to see if the x-robots-tag is being used, and which directives are being used.
As you can guess, this can easily slip through the cracks unless you are specifically looking for it. Imagine checking a site for the meta robots tag, thinking all is ok when you can’t see it, but the x-robots-tag is being used with “noindex, nofollow” on every url. Not good, to say the least.
How To Check The X-Robots-Tag in the Header Response
Based on what I explained above, I decided to write this post to explain several different ways to check for the x-robots-tag. By adding this to your checklist, you can ensure that important directives are correct and that you are noindexing and nofollowing the right pages on your site (and not important ones that drive a lot of traffic from Google and/or Bing). The list below contains tools directly from Google, Chrome extensions, and third-party crawling tools for checking urls in bulk. Let’s jump in.
1. Tools Directly From Google
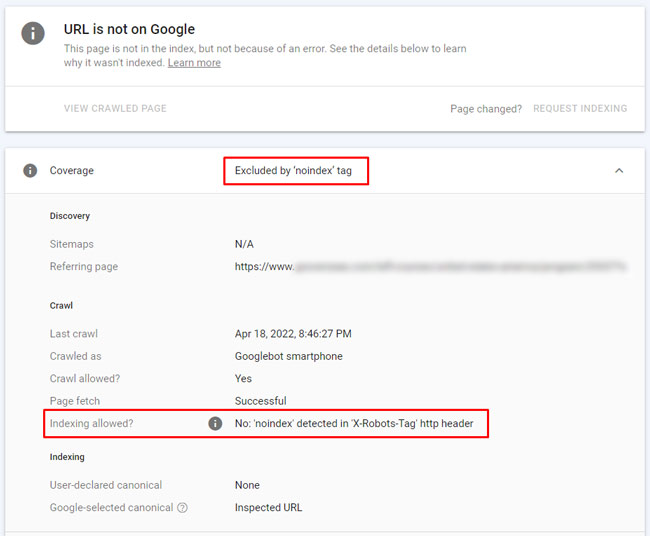
Google’s URL Inspection Tool
There’s nothing better than going straight to the source. With Google’s URL Inspection Tool, you can check specific urls to see if they are indexable. And as you can guess, the tool will specify if noindex is being delivered via the x-robots-tag (via the header response).
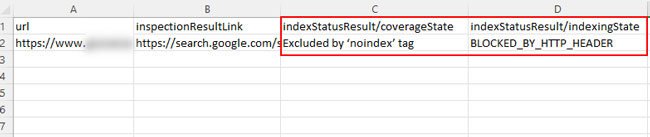
URL Inspection API
You can also use Google’s URL Inspection API to test urls in bulk. Once you run urls through the API, you can see if they are being noindexed via the x-robots-tag. You can check my tutorial for creating a multi-site indexing monitoring system to learn more about how to use the API.
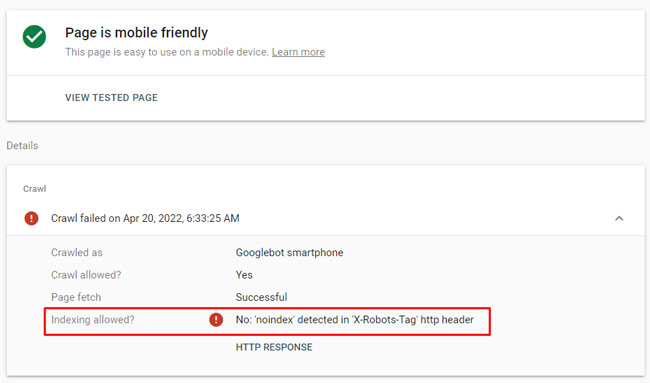
Mobile-friendly Test
Google’s mobile-friendly test can also show you if a page is being noindexed via the x-robots-tag. And since the tool can check any public url, you don’t need to have the site verified in GSC.
2. Chrome Extensions
Web Developer Plugin
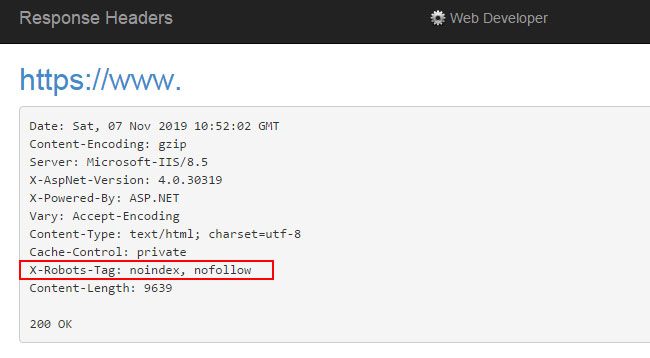
The web developer plugin is one of my favorite plugins for checking a number of important items, and it’s available for both Firefox and Chrome. By simply clicking the plugin in your browser, then “Information”, and then selecting “Response Headers”, you can view the http header values for the url at hand. And if the x-robots-tag is being used, you will see the values listed.
Detailed SEO chrome extension
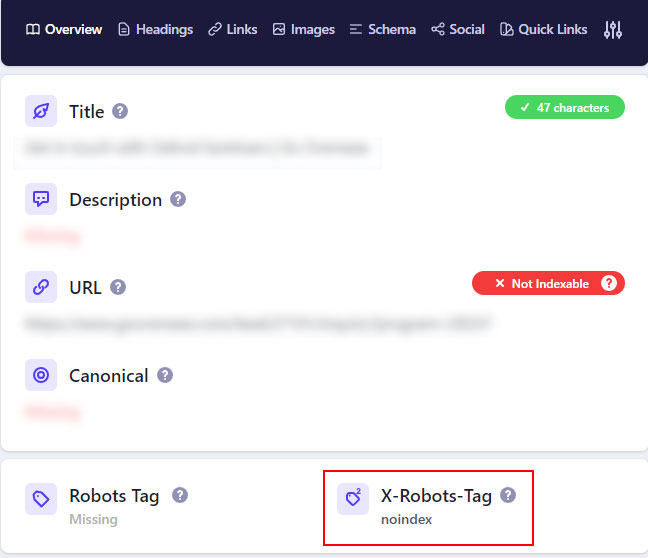
The Detailed SEO extension provides a boatload of SEO information based on the page you are analyzing. And yes, it includes the x-robots-tag. One quick click and you can view if the page is being noindexed via the x-robots-tag. I highly recommend this plugin overall, and for checking the x-robots-tag. I think you’ll dig it.
Robots Exclusion Checker
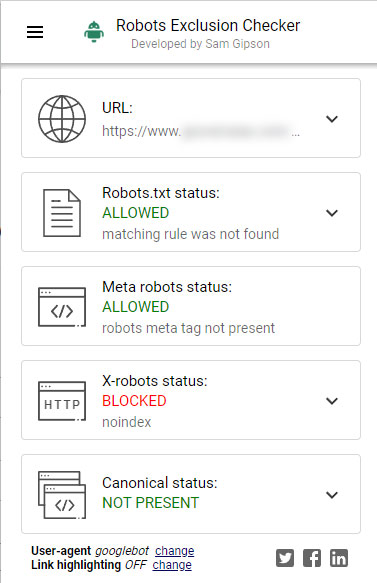
This is another one of my favorite chrome extensions. The Robots Exclusion Checker will check the status of the robots.txt file, meta robots tag, x-robots-tag, and canonical url tag. I use this plugin often and it works extremely well for checking the x-robots-tag.
3. Crawling Tools
Now that I’ve covered Google’s tools and some Chrome extensions for checking the x-robots-tag, let’s check out some robust third-party crawling tools. For example, if you want to crawl many urls in bulk (like 10K, 100K, or 1M+ pages) to check for the presence of the x-robots-tag, then the following tools can be extremely helpful.
DeepCrawl
If you want to a robust, enterprise-level crawling engine, then DeepCrawl is for you. Note, I’ve been such a big proponent of DeepCrawl that I was on the customer advisory board for years. So yes, I’m a fan. :)
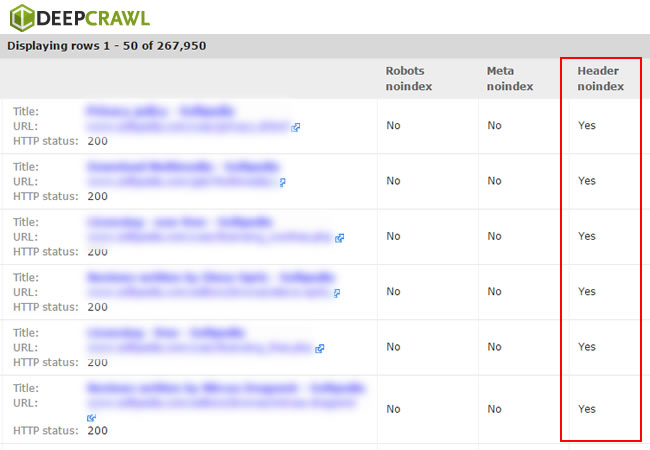
After crawling a site, you can easily check the “Noindex Pages” report to view all pages that are noindexed via the meta robots tag, the x-robots-tag header response, or by using noindex in robots.txt. You can export the list and then filter in Excel to isolate pages noindexed via the x-robots-tag.
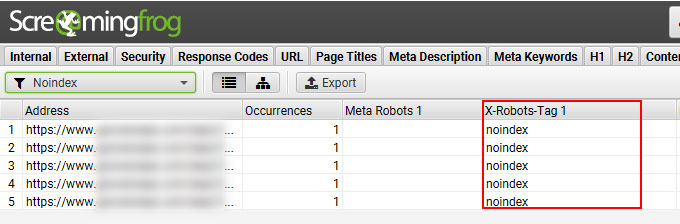
Screaming Frog
I’ve also been a big fan of Screaming Frog for a long time. It’s an essential tool in my SEO arsenal and I often use Screaming Frog in combination with DeepCrawl. For example, I might crawl a large-scale site using DeepCrawl and then isolate certain areas for surgical crawls using Screaming Frog.
Once you crawl a site using Screaming Frog, you can simply click the Directives tab and then look for the x-robots column. If any pages are using the x-robots-tag, then you will see which directives are being used per url.
Sitebulb
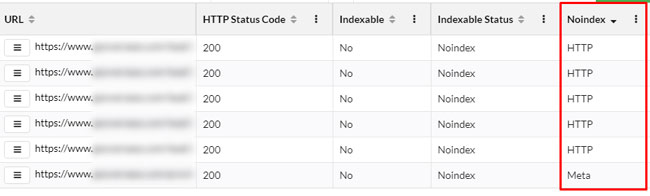
Sitebulb is another excellent crawling tool and it also provides information based on the x-robots-tag. You can find that information in the Indexability section and then the Noindex reporting. I use Sitebulb often while analyzing websites.
JetOctopus
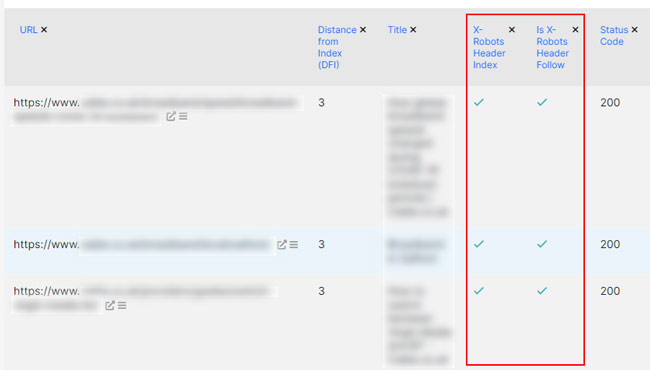
I’ve also started using JetOctopus for crawling websites, which is another excellent enterprise-level crawling tool. And as you can guess, it reports on the x-robots-tag as well. Not as many people in the industry know about JetOctopus, but it’s a solid crawling tool that I’m using more and more.
Summary – There’s more than one way to noindex a page…
OK, now there’s no excuse for missing the x-robots-tag during an SEO audit. :) If you notice certain pages are not being indexed, yet the meta robots tag isn’t present in the html code, then you should definitely check for the presence of the x-robots-tag. You just might find important pages being noindexed via the header response. And again, it could be a hidden problem that’s causing serious SEO issues.
Moving forward, I recommend checking out the various tools, Chrome extensions, and crawlers I listed in this post. All can help you surface important directives that can be impacting your SEO efforts.
GG