
If you are confused when Google reports redirects as other categories, like “blocked by robots.txt”, “soft 404s”, “noindexed”, “404s”, and others, it could be Google silently following the redirect and reporting the status of the true destination url instead. My post covers the situation in detail, and provides examples of this happening in the wild.
While heavily analyzing websites from an SEO standpoint, you will undoubtedly find yourself deep in Google Search Console (GSC) reporting. GSC contains a boatload of data directly from Google and can help site owners and SEOs surface key insights. That said, it’s important to understand the nuances involved with GSC reporting, and how Google determines the information it provides in those reports. Having a clear understanding of what the data is showing is important when taking action to improve SEO.
And there’s no better example of GSC data confusion than the dreaded true destination url for redirects in GSC’s index coverage reporting (and URL inspection tool). I have received so many questions about this from clients that I decided to write this post so I can just point people here versus explaining it again and again.

So, join me on a GSC adventure where we uncover the secrets of the true destination url. Some of you might already know this, but I know some do not. And for those that don’t, this will all make sense very soon. You might not be happy with how this is working, but at least you’ll understand why urls are categorized in certain ways in GSC (and via the URL inspection tool).
What is the dreaded true destination url situation in GSC for redirects?
When viewing the indexing status in GSC of urls that are being redirected, Google reports on the true destination url (even if that url is outside of your own site). For example, if you redirect a url to another url, and that url is not indexable for some reason, GSC will silently follow the redirect and report on the final destination’s status. And that can be super confusing for site owners and SEOs that don’t know this is happening.
Yes, that means you can see urls showing up as “blocked by robots.txt”, “noindexed”, “soft 404”, “404”, and more (when the url you are inspecting is actually redirecting). As you can imagine, many site owners are left confused when they see “blocked by robots.txt” when they know 100% that a url is redirecting.
Google’s John Mueller has been asked about this many times, and he has replied with what I explained above (and does admit it can be a bit confusing). Also, Barry wrote a post covering how this happens with the URL inspection tool based on John’s comments. Even though this has been documented, I find it’s still a very confusing situation for many site owners and SEOs (which is why I’m writing this post).
Here is a tweet of mine with a link to John explaining how Google silently follows redirects (and how that shows up in GSC):
Now that you know this is happening, you might be wondering what this actually looks like in GSC. I’ll cover that next with examples of this happening in the wild.
Examples of Google silently following redirects and reporting the true destination url status in GSC:
Below, I’ll provide examples with screenshots of Google reporting on the true destination urls versus the redirect. Again, this is when the final destination urls are not indexable for some reason.
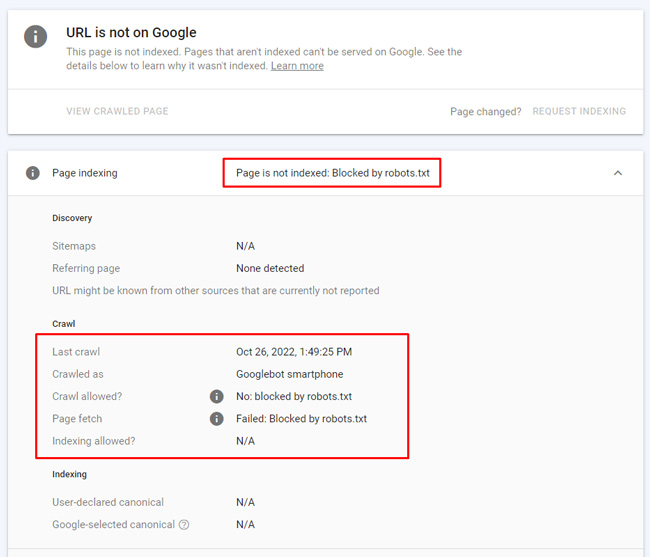
Blocked by robots.txt:
The url is redirected outside the site to a url that is blocked by robots.txt. Google reports the redirecting url as being “blocked by robots.txt” since the final destination is actually disallowed.
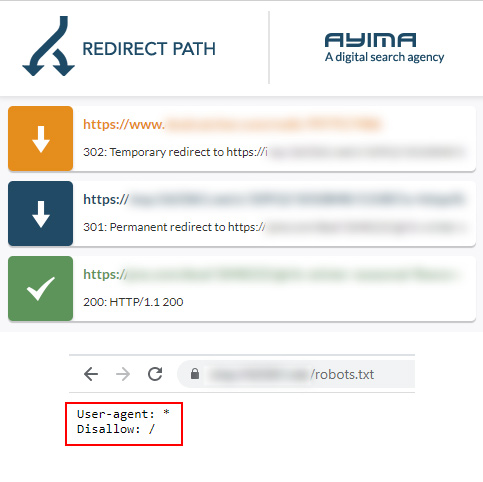
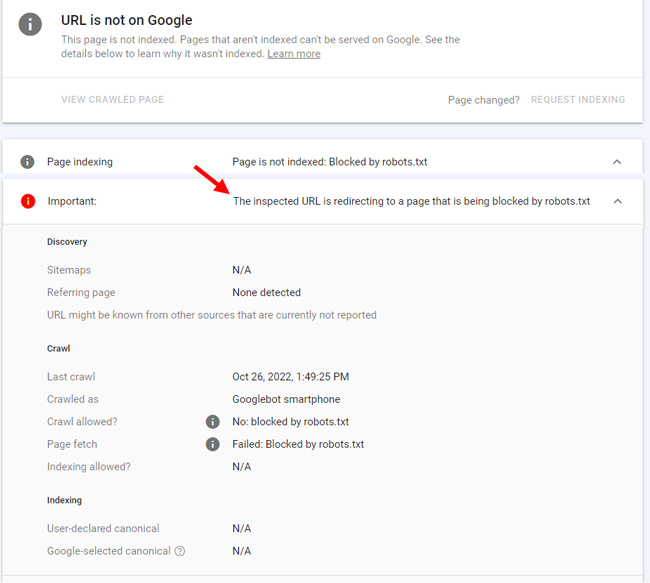
A twist on blocked by robots.txt:
This url redirects first to a tracking url, which is blocked by robots.txt. The final destination is not blocked, but Google can’t follow the first redirect to find the final destination url since it’s disallowed. It just knows that first url in the chain is blocked and reports that in GSC. Below, you can see the second step shows the url is actually blocked by robots.txt (and that’s what is reported in GSC).
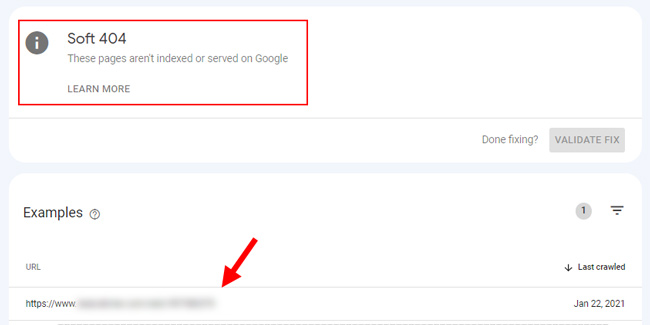
Soft 404:
The url redirects to a page that’s a soft 404 (a product is unavailable). Google reports that the redirecting url is a soft 404 (since the true destination url is being seen as a soft 404).
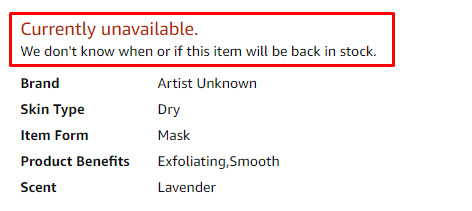
Here is the page the url redirects to (with the product “currently unavailable”). Hence the soft 404:
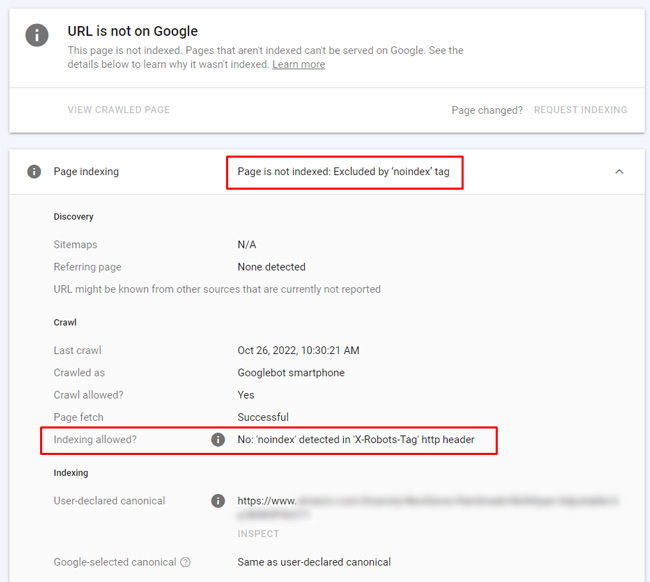
Noindexed:
Yep, you guessed it. The url redirects to a page that’s noindexed. Google reports the url that is redirecting as noindexed in the coverage reporting:
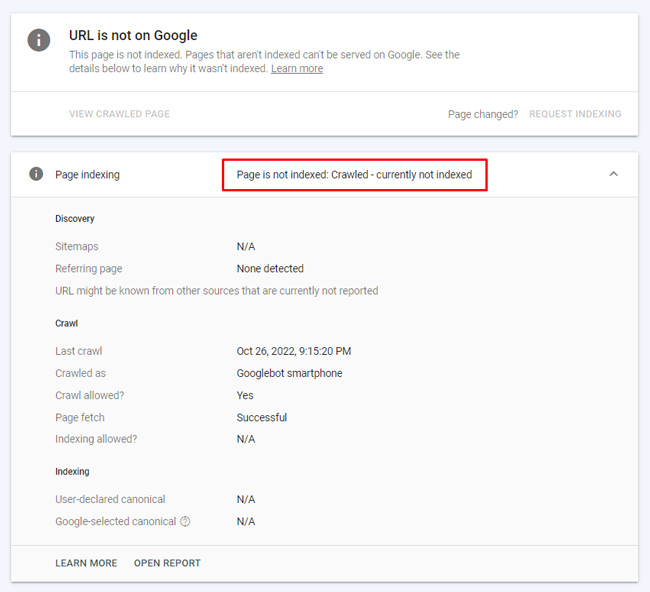
Crawled, not indexed:
At first glance, you might think the redirect is being reported as “Crawled, not indexed”. Not true! It’s the final destination url that’s not being indexed by Google. Google is reporting “Crawled, not indexed” for the true destination url.
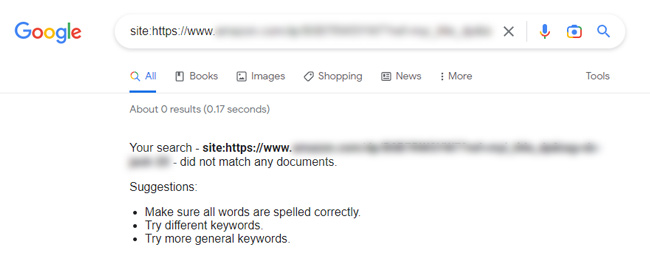
The final destination url is indeed not indexed:
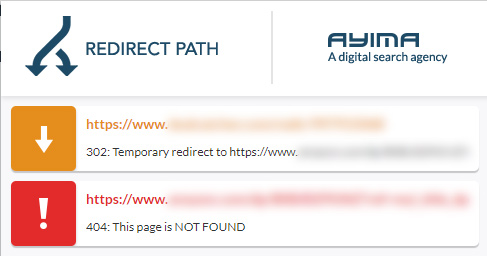
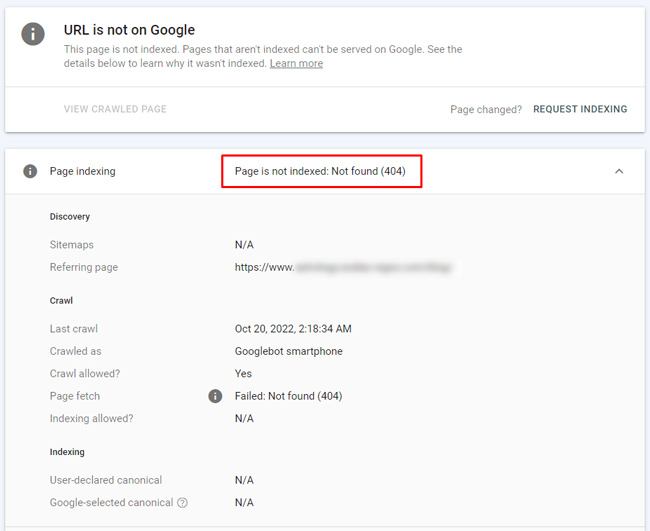
404:
How can Google see a redirect as a 404? It doesn’t. It’s the true destination url that 404s and that’s what is reported in GSC.
404 with domain name change:
This is just a variation on the 404 situation to explain how this works when changing domain names. The url on the old domain redirects to a url on the new domain name, but the url was never migrated (it 404s). So Google reports that the redirecting url is a 404.

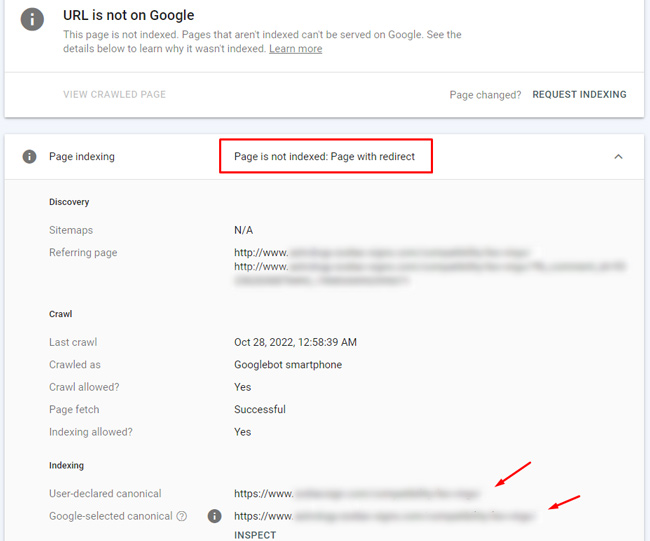
Sorry, more confusion with redirects:
When a url redirects to a page that resolves with a 200 header response code, and is indexed, the URL inspection tool reports accurately about the redirect (and says that initial url is a redirect and not indexed), but Google shows the canonical as the true destination url (where the redirect leads to). Talk about confusing, especially based on everything I explained above with the other examples where the redirecting urls are being reported as something different than a redirect…
A possible solution in GSC to clear up the confusion:
So, how can this be more intuitive? I think if GSC actually provided a message that it’s reporting on the true destination url, it could clear up the confusion for site owners and SEOs. Below, I have mocked up what this can look like in GSC. If Daniel Waisberg is reading (and I hope you are), then please add this!
Summary: Clearing up the confusion with redirects and destination url reporting.
I hope this post helped you understand how Google is silently following redirects and reporting on the true destination urls in GSC. I know it’s a confusing topic for many site owners and SEOs and I’m sure it has led to many head-scratching moments. Just keep in mind that as of now, GSC is reporting on the true destination urls when a url redirects. So don’t be surprised when you notice redirects in other categories in GSC’s coverage reporting (or when using the url inspection tool). And who knows, maybe the GSC product team will implement that message I mocked up above…
GG