
Based on helping clients with Panda work, Penguin problems, SEO technical audits, etc., I end up crawling a lot of websites. In 2014, I estimate that I crawled over eleven million pages while helping clients. And during those crawls, I often pick up serious technical problems inhibiting the SEO performance of the sites in question.
For example, surfacing response code issues, redirects, thin content, duplicate content, metadata problems, mobile issues, and more. And since those problems often lie below the surface, they can sit unidentified and unresolved for a long time. It’s one of the reasons I believe SEO technical audits are the most powerful deliverable in all of SEO.
Last week, I found an interesting comment from John Mueller in a Google Webmaster Hangout video. He was speaking about the canonical url tag and explained that Google needs to process rel canonical as a second or third step (at 48:30 in the video). He explained that processing rel canonical signals is not part of the crawling process, but instead, it’s handled down the line. And that’s one reason you can see urls indexed that are canonicalized to other pages. It’s not necessarily a problem, but gives some insight into how Google handles rel canonical.
When analyzing my tweets a few days later, I noticed that specific tweet got a lot of eyeballs and engagement.

That got me thinking that there are probably several other questions about rel canonical that are confusing webmasters. Sure, Google published a post covering some common rel canonical problems, but that doesn’t cover all of the issues webmasters can face. So, based on crawling over eleven million pages in 2014, I figured I would list some dangerous rel canonical issues I’ve come across (along with how to rectify them). My hope is that some readers can leave this post and make changes immediately. Let’s jump in.
1. Canonicalizing Many URLs To One
When auditing websites I sometimes come across situations where entire sections of content are being canonicalized to one url. The sections might contain dozens or urls (or more), but the site is using the canonical url tag on every page in the section pointing to one other page on the site.
If the site is canonicalizing many pages to one, then it will have little chance of ranking for any of the content on the canonicalized pages. All of the indexing properties will be consolidated to the url used in the canonic al url tag (in the href). Rel canonical is meant to handle very similar content at more than one url, and was not meant for handling many pages of unique content pointing to one other page.
When explaining this to clients, they typically didn’t understand the full ramifications of implementing a many to one rel canonical strategy. By the way, the common reason for doing this is to try and boost the rankings of the most important pages on the site. For example, webmasters believe that if they canonicalize 60 pages in a section to the top-level page, then that top-level page will be the all-powerful url ranking in the SERPs. Unfortunately, while they are doing that, they strip away any possibility of the canonicalized pages ranking for the content they hold. And on larger sites, this can turn ugly quickly.

If you have unique pages with valuable content, then do not canonicalize them to other pages… Let those pages be indexed, optimize the pages for the content at hand, and make sure you can rank for all of the queries that relate to that content. When you take the long tail of SEO into account, those additional pages with unique content can drive many valuable visitors to your site via organic search. Don’t underestimate the power of the long tail.
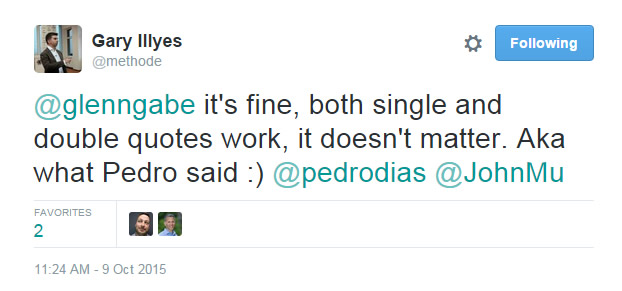
Quick Tip: Can You Use Single Quotes Versus Double Quotes In The Canonical URL Tag?
There has been some confusion regarding the use of single quotes versus double quotes when using rel canonical (in the code). For example, <link rel=“canonical” href=“page1.htm” /> versus <link rel=’canonical’ href=’page1.htm’ />. I’ve always believed you could use either single or double quotes, but some strongly believe you must use double quotes. So I asked Google’s Gary Illyes on Twitter. It ends up I was right. Google is fine with both. See the tweet below.
2. Daisy Chaining Rel Canonical
When using the canonical url tag, you want to avoid daisy chaining hrefs. For example, if you were canonicalizing page2.htm to page1.htm, but page 1.htm is then canonicalized to page3.htm, then you are sending very strange signals to the engines. To clarify, I’m not referring to actual redirects (like 301s or 302s), but instead, I’m talking about the hrefs used in the canonical url tag.
Here’s an example:
page 2.htm includes the following: <link rel=“canonical” href=“page1.htm” />
But page1.htm includes this: <link rel=“canonical” href=“page3.htm” />

While conducting SEO audits, I’ve seen this botched many times, even beyond the daisy chaining. Sometimes page3.htm doesn’t even exist, sometimes it redirects via 301s or 302s, etc.
Overall, don’t send mixed signals to the engines about which url is the canonical one. If you say it’s page1.htm but then tell the engines that it’s page3.htm once they crawl page1.htm, and then botch page3.htm in a variety of ways, you might experience some very strange ranking problems. Be clear and direct via rel canonical.
3. Using The Non-Canonical Version
This situation is a little different, but can cause problems nonetheless. I actually just audited a site that used this technique across 2.1M pages. Needless to say, they will be making changes asap. In this scenario, a page is referencing a non-canonical version of the original url via the canonical url tag. But the non-canonical version actually redirects back to the original url.
For example:
page1.htm includes this: <link rel=“canonical” href=“page1.htm?id=46” />
But page1.htm?id=46 redirects back to page1.htm

So in a worst-case scenario, this is implemented across the entire site and can impact many urls. Now, Google views rel canonical as a hint and not a directive. So there’s a chance Google will pick up this error and rectify the issue on its end. But I wouldn’t bank on that happening. I would fix rel canonical to point to the actual canonical urls on the site versus non-canonical versions that redirect to the original url (or somewhere else).
4. No Rel Canonical + The Use of Querystring Parameters
This one is simple. I often find websites that haven’t implemented the canonical url tag at all. For some smaller and less complex sites, this isn’t a massive problem. But for larger, more complex sites, this can quickly get out of control.
As an example, I recently audited a website that heavily used campaign tracking parameters (both from external campaigns and from internal promotions). By the way, don’t use campaign tracking parameters on internal promotions… they can cause massive tracking problems. Anyway, many of those urls were getting crawled and indexed. And depending on how many campaigns were set up, some urls had many non-canonical versions being crawled and indexed.
![]()
By implementing the canonical url tag, you could signal to the engines that all of the variations of urls with querystring parameters should be canonicalized to the original, canonical url. But without rel canonical in place, you run the risk of diluting the strength of the urls in question (as many different versions can be crawled, indexed, and linked to from outside the site).
Imagine 500K urls indexed with 125K duplicate urls also indexed. And for some urls, maybe there are five to ten duplicates per page. You can see how this can get out of control. It’s easy to set up rel canonical programmatically (either via plugins or your own server-side code). Set it up today to avoid a situation like what I listed above.
5. Canonical URL Tag Not Present on Mobile Urls (m. or other)
Mobile has been getting a lot of attention recently (yes, understatement of the year). When clients are implementing an m. approach to mobile handling, I make sure to pay particular attention the bidirectional annotations on both the desktop and mobile urls. And to clarify, I’m not just referring to a specific m. setup. It can be any mobile urls that your site is using (redirecting from the desktop urls to mobile urls).
For example, Google recommends you add rel alternate on your desktop urls pointing to your mobile urls and then rel canonical on your mobile urls pointing back to your desktop urls.

This ensures Google understands that the pages are the same and should be treated as one. Without the correct annotations in place, you are hoping Google understands the relationship between the desktop and mobile pages. But if it doesn’t, you could be providing many duplicate urls on your site that can be crawled and indexed. And on larger-scale websites (1M+ pages), this can turn ugly.
Also, contrary to what many think, separate mobile urls can work extremely well for websites (versus responsive or adaptive design). I have a number of clients using mobile urls and the sites rank extremely well across engines. You just need to make sure the relationship is sound from a technical standpoint.
6. Rel Canonical to a 404 (or Noindexed Page)
The last scenario I’ll cover can be a nasty one. This problem often lies undetected until pages start falling out the index and rankings start to plummet. If a site contains urls that use rel canonical pointing to a 404 or a noindexed page, then the site will have little shot of ranking for the content on those canonicalized pages. You are basically telling the engines that the true, canonical url is a 404 (not found), or a page you don’t want indexed (a page that uses the meta robots tag containing “noindex”).
I had a company reach out to me once during the holidays freaking out because their organic search traffic plummeted. After quickly auditing the site, it was easy to see why. All of their core pages were using rel canonical pointing to versions of that page that returned 404 header response codes. The site (which had over 10M pages indexed) was giving Google the wrong information, and in a big way.

Once the dev team implemented the change, organic search traffic began to surge. As more and more pages sent the correct signals to Google, and Google indexed and ranked the pages correctly, the site regained its traffic. For an authority site like this one, it only took a week or two to regain its rankings and traffic. But without changing the flawed canonical setup, I’m not sure it would ever surge back.
Side Note: This is why I always recommend checking changes in a staging environment prior to pushing them live. Letting your SEO review all changes before they hit the production site is a smart way to avoid potential disaster.
Summary – Don’t Botch Rel Canonical
I’ve always said that you need a solid SEO structure in order to rank well across engines. In my opinion, SEO technical audits are worth their weight in gold (and especially for larger-scale websites.) Rel canonical is a great example of an area that can cause serious problems if not handled correctly. And it often lies below the surface, wreaking havoc by sending mixed signals to the engines.
My hope is that the scenarios listed above can help you identify, and then rectify canonical url problems riddling your website. The good news is that the changes are relatively easy to implement once you identify the problems. My advice is to keep rel canonical simple, send clear signals, and be consistent across your website. If you do that, good things can happen. And that’s exactly what you want SEO-wise.
GG
Excellent post Glenn – Lot of stuff I wasnt aware of – much appreciated.
Thanks Jim! I’m glad my post was helpful. I think I need to write a “Part 2” soon. There are several other dangerous rel canonical issues out there… :)
How to Shoot Yourself in the Foot using rel canonical
That’s exactly right. And since it sits in the source code, it’s hard for many marketers to surface. A dangerous recipe for sure.
Nice tips Glenn. I recently came across a rel=canonical issue for a publisher with separate mobile sites, where the rel=canonical tag in the source code of the mobile pages was correct, but there was also an incorrect (i.e. self-referencing) rel=canonical declaration in the HTTP header. It turned out to something inadvertent related to a recent migration, but since the HTTP header was getting hit first this was interfering with the bi-directional annotations. So even when you get your rel=canonical tags right you can still get it wrong. :)
Hey, that’s a great example Adam. If Google comes across two rel canonical declarations, it will ignore them both. So what you found certainly helped your client. :)
Here’s a quote from Google (from their common problems page) -> “Specify no more than one rel=canonical for a page. When more than one is specified, all rel=canonicals will be ignored.”
Thanks Glenn. I was thinking the first one was superseding the second. I’d forgotten about that guidance on both being ignored.
Hey Glenn, Great post. What are your thoughts about rel=canonical pagination? For example if I have 200 widgets for sale on my site with 4 pages of that same widget (50 per page). Would it be ok to rel=canonical pages 2,3 & 4 all back to the first page? (G is already ranking the first page already but not ranking 2, 3 & 4)
Great question Shawn. I can write an entire post about pagination! Google actually listed pagination in its own post about rel canonical mistakes (the link is included above in my post).
For ecommerce pagination, you shouldn’t canonicalize component pages to the first page. That’s not the proper use of the canonical url tag. Instead, you should use rel next/prev to inform the engines about the relationship between the component page and the paginated series. You can read more about rel next/prev here -> http://googlewebmastercentral.blogspot.com/2011/09/pagination-with-relnext-and-relprev.html
I hope that helps!
That’s exactly right Emory. It’s a great example of how one line of code could destroy your SEO. Simple, yet dangerous if not handled properly. :)
I’ve come across some pages in my company’s website that is using a Rel=canonical to point to their own URL.
For example, the page http://www.website.com/product/productnumber has this Rel=canonical in the :
Can you use a Rel=canonical to point to its own page?
If so, what are the advantages?
If not, why?
Thanks
Yes, you absolutely can use a self-referencing rel canonical tag. It ensures that any variation of that url will contain the proper canonical url tag.
For example, a url might contain campaign parameters if you are running advertising campaigns. Using a self-referencing canonical url tag would consolidate indexing properties from across all non-canonical urls. It’s very common to use rel canonical that way. I hope that helps.
We have separate urls for desktop and mobile. We are adhering to the 2 way annotation (i.e. rel=’alternate’ on desktop and rel=’canonical’ on mobile). In desktop pages where we have pagination, we are using rel – prev/ next as suggested. But for the corresponding mobile pages (which have pagination) we are using just the rel=’canonical’ (part of the 2 way annotation system). Should we start using rel prev/ next as well for these corresponding mobile pages? will that make sense?
Rel next/prev and rel canonical are independent concepts. You can use rel canonical while also using rel next/prev. For your mobile pages, if you have the proper bidirectional tags set up (rel alternate + rel canonical), then I’m not sure rel next/prev is necessary. It probably wouldn’t hurt you if you added them, but it doesn’t seem necessary. I hope that helps.
Good Insights! Though, I wish to ask, In writing canonical code will there be an effect in SEO if we put it this way without the http and the www or is should be written with http and www.
Technically, you can use both relative and absolute URLs, but I’ve seen many cases of relative URLs causing issues (if they aren’t entered accurately).
Google even recommends using absolute URLs when adding rel canonical. So if you can, use absolute URLs. I hope that helps.
Hi Glenn, thanks for your great article. I have a question and find so far no answer on the web. It would be great if you can tell me something about that
I have a page http://www.school.com/exams/german-level-a1/ with subpages exam-date-1, exam-date-2, 3 and so on.
The question: should I make a cononical “redirection” from exam-date-n to /german-level-1?
both pages do not have similar content…
I would need to see the pages, content, and actual setup. Very hard to say without seeing that.
Thanks James. And yes, that’s exactly the type of canonical error that can cause all sorts of problems. I’m glad you caught that and fixed the problem.
Regarding the screenshot, that’s from DeepCrawl, which is I use often for large-scale crawls. I’m on the customer advisory board for DeepCrawl as well.