Several site owners have reached out to me recently about a scary spike in indexing that then drops back down to normal levels. This is showing up in the coverage reporting in Google Search Console and the site owners thought it could be a sign of something terrible happening SEO-wise. For example, Google suddenly indexing urls it shouldn’t and maybe that possibly impacting site quality overall. That’s not the case for most sites, and I’ll explain what the issue was below. And it’s worth noting that I have seen this a number of times over the years. It ends up the answer is right there in the reporting, but can be tricky to see at first glance.
Double Vision: Don’t forget to scroll down in the coverage reporting and review “Indexed, though blocked by robots.txt”
It’s easy to miss that yellow/orange addition at the bottom of the coverage reporting. The report covers “Indexed, though blocked by robots.txt” and that can often explain a sudden surge, and then drop, in indexing overall for a site. But I find many site owners don’t know to look there, or still don’t know if that’s a huge problem from an SEO standpoint even if they do see that.
I think one of the most confusing things about that report is that when it surges, so does overall indexing for the site. And that makes sense if you think about it. The top report for page indexing shows all pages indexed by Google. And urls that are indexed, though blocked by robots.txt are technically indexed. So they should show up there. But again, that’s very confusing for some site owners. I’ll cover more about this situation below.
For example, here are two sites that saw a spike in indexing, but it drops back down pretty quickly. If you check “Indexed, though blocked robots.txt” in Search Console, you can see the same trending from an indexing standpoint. Yep, that’s where the spike and drop happened. And that’s totally fine from an SEO perspective.
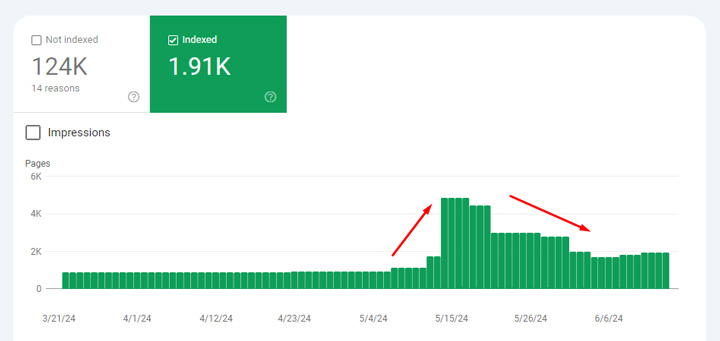
And “Indexed, though blocked by robots.txt” shows the same spike and drop:
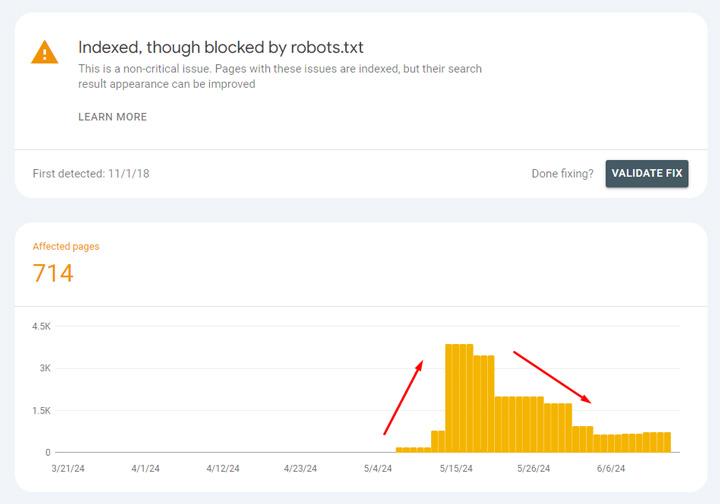
Here’s another example of a spike in indexing, but it drops back down quickly:
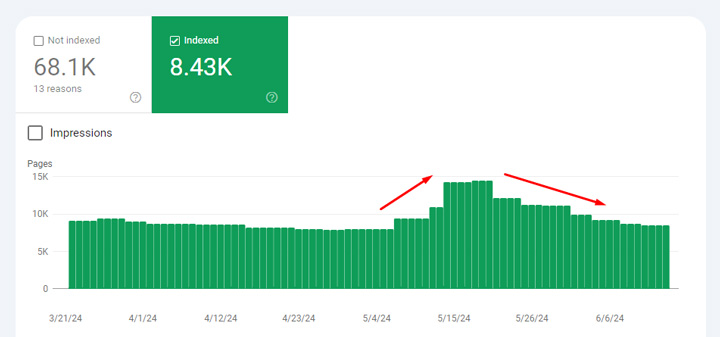
And again, “Indexed, though blocked by robots.txt” shows the same spike and drop:
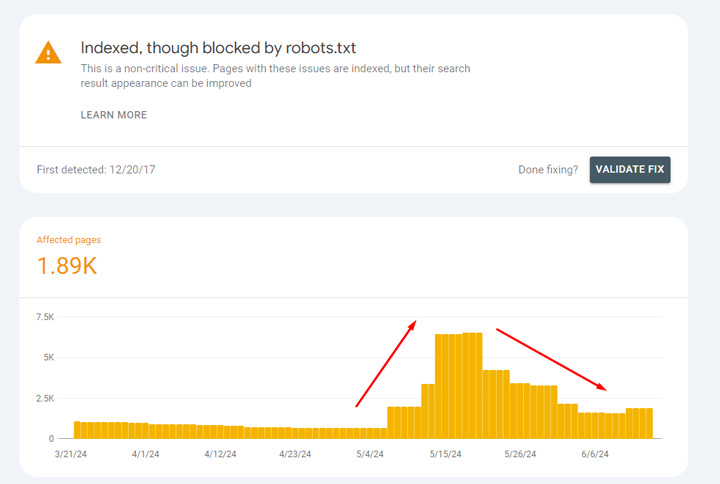
Reasons for the spike in indexing in Search Console:
First, blocking urls via robots.txt does not stop pages from being indexed. Google has explained this many times before and it’s literally in their documentation. Google can still index the urls, but without crawling the content. For example, if Google picks up links to those urls, then they can end up getting indexed (but without Google actually crawling the page content).
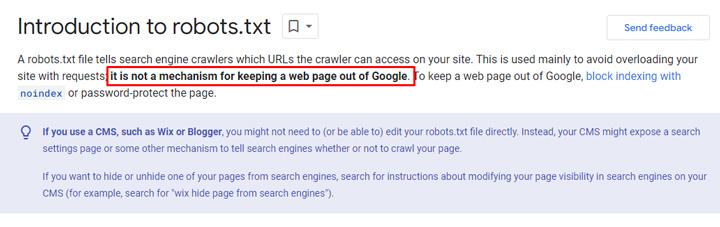
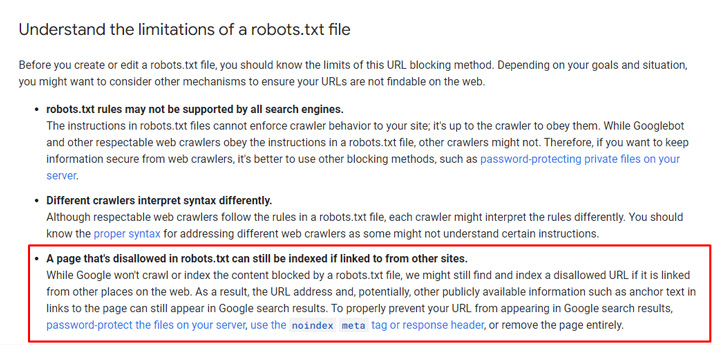
Also, if those pages end up in ranking in the SERPs (which they can sometimes), Google just provides a message that a snippet could not be generated and links to its documentation covering why you might be seeing that message. And as you can guess, it includes information about blocking via robots.txt possibly being a cause for that.
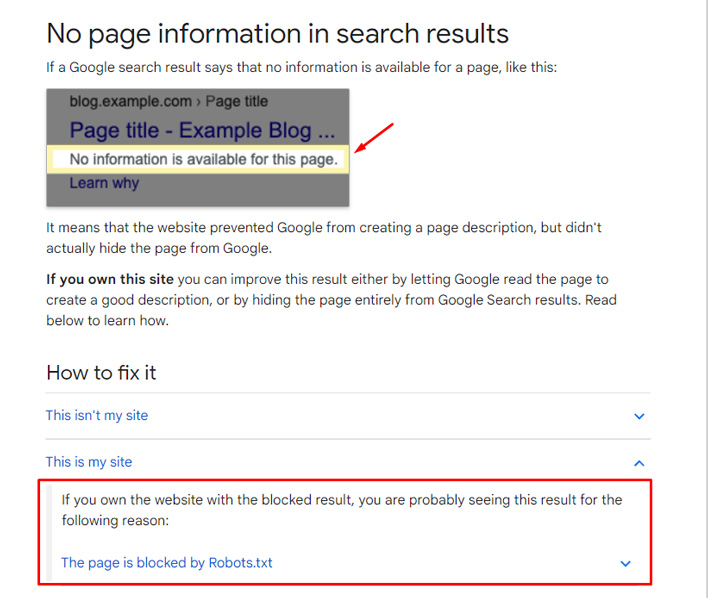
So yes, Google chose to index those urls, but no, it’s not going to cause a huge problem from an SEO standpoint, a site quality perspective, and it won’t impact rankings negatively. I’ll cover why that’s the case next. Also, and as you can see from the graphs above, Google’s systems decided to deindex those urls not long after indexing them.
Why spikes in “Indexed, but blocked by robots.txt” is not a problem (usually).
After seeing the number of urls spike in “Indexed, though blocked by robots.txt” over the years, and wondering how those urls could impact Google’s quality evaluation of a site, I decided to ask Google’s John Mueller about this in a Search Central Hangout video in 2021. John explained that urls blocked by robots.txt would not have an impact quality-wise since Google could not crawl the urls and see the content there. You can see my tweet about this below, which contains a link to the video with John.
And here is another clip from John covering “Indexed, though blocked by robots.txt” specifically. John explains that it’s more of a warning for site owners in case they wanted those urls indexed. If they don’t want them crawlable, and they definitely want the urls blocked by robots.txt, then it’s totally fine. And he explained again that the urls cannot be held against the site since Google cannot crawl the content.
Summary: Not all sudden spikes in indexing are scary and problematic. And make sure to check ALL of the reports in GSC.
The next time you see a sudden spike in indexing, and possibly a drop, make sure to check out the report at the very bottom of the coverage reporting in Search Console. The answer might simply be urls that are “Indexed, though blocked by robots.txt”. And if that’s the case, you might have absolutely nothing to worry about. Those urls are technically indexed, but Google can’t crawl the content so they can’t be held against the site from a quality perspective. And if that’s the case, then breathe a sigh of relief and move on to more important things SEO-wise.
GG