Four methods and only two are correct. In this article, I’ll cover the various ways I have seen site owners try to block content that’s violating Google’s site reputation abuse spam policy (including actual examples of how those methods worked, or didn’t).

Update: March 12, 2025
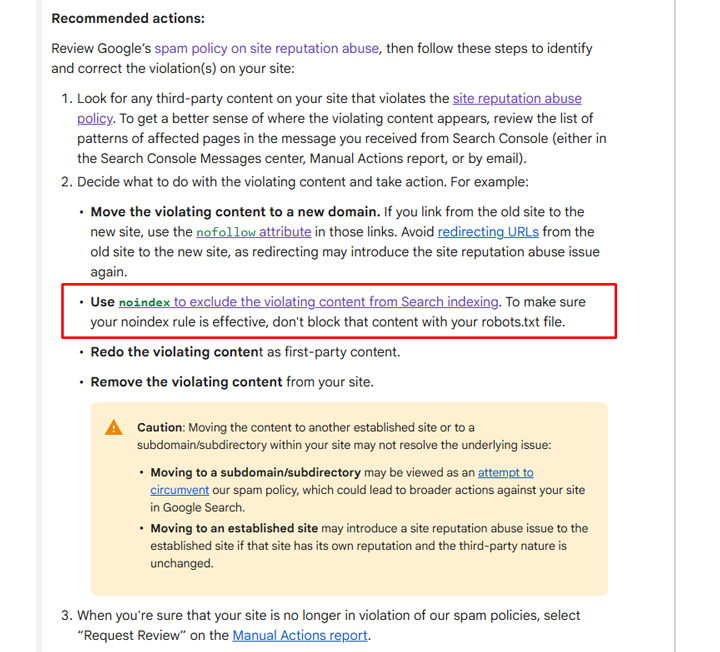
Google just updated its documentation for manual actions clearly explaining to noindex the urls and to NOT disallow via robots.txt. It’s great they finally added a clear message in the documentation for site owners. Learn more.
—————
Last year I wrote a post explaining why an algorithmic approach to handling site reputation abuse was the way forward for Google (versus applying manual actions). Handling the situation algorithmically would obviously be a much more scalable approach, Google would catch more content violating the policy, and the webspam team wouldn’t be making one-off decisions about which sites should receive a manual action.
Well, fast forward to today and Google is still using manual actions to deal with site reputation abuse, and some sites are still slipping through the cracks. In addition, there are some sites not handling the blocking of content correctly from a technical SEO standpoint. For example, they know they have content violating Google’s site reputation abuse policy, but they are not blocking that content properly. And that means the content can still rank, it could lead to a manual action, etc.
I’ve seen enough weird technical SEO situations over the past few months with site reputation abuse that I decided to write a post to clear up any confusion about the correct approach for blocking content. Below, I’ll cover more about correctly handling site reputation abuse from a technical SEO standpoint, while providing examples of what I’m seeing in the wild.
First, a note about Google’s ‘starkly different’ algorithm:
We know Google has been improving its systems for identifying when a section of content is ‘independent or starkly different’ from the main content of the site. I reported about that in my post titled, “A Nightmare on Affiliate Street”, where I covered how sections on authoritative sites were dropping since they were not benefitting from sitewide signals anymore (so they plummeted in rankings).
It would make sense for Google to leverage those systems as the basis for handling site reputation abuse algorithmically, but Google has explained we probably won’t see an algorithmic approach any time soon (at least fully). The problem is that Google needs to get those systems to a point where they doesn’t cause mass collateral damage. So as of now, Google is employing manual actions to address site reputation abuse.
For example, Google just rolled out manual actions in two waves recently for sites in Europe. Regardless, I would get your technical SEO situation in order so you don’t run into any problems either via manual actions or an algorithm update that addresses site reputation abuse.
Here is information from Google’s blog post explaining more about its ‘starkly different’ system:
Four ways sites are handling site reputation abuse, and why only two are correct. I’ll start with the incorrect methods:
1. Blocking via robots.txt. NOT VALID
First, blocking via robots.txt is not a valid approach for dealing with a manual action for site reputation abuse. I know this confuses many site owners, but disallowed pages can still be indexed and can still rank, but just without Google crawling the content. Even in Google’s documentation about how to handle content violating its site reputation abuse policy, Google doesn’t provide ‘blocking via robots.txt’ as a solution. I also covered this in my first article about site reputation abuse…
For keeping content from being indexed, blocking via robots.txt is only a valid approach for images and video, and not html documents. Therefore, it’s not the right way to handle content violating Google’s site reputation abuse policy.
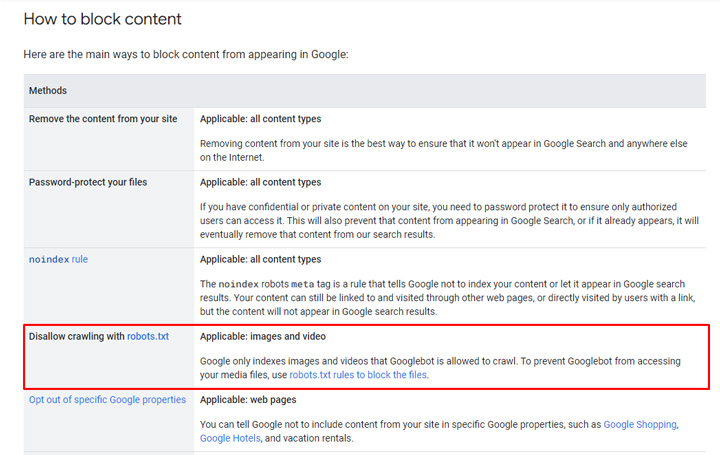
We actually just saw this play out with the latest round of manual actions in Europe. The following site somehow got out of the manual action but was both noindexing the content AND blocking via robots.txt. The problem is that Google cannot crawl the content to see the noindex tag. Therefore, Google can still index the pages, but without crawling the content. And yes, those pages can still rank.
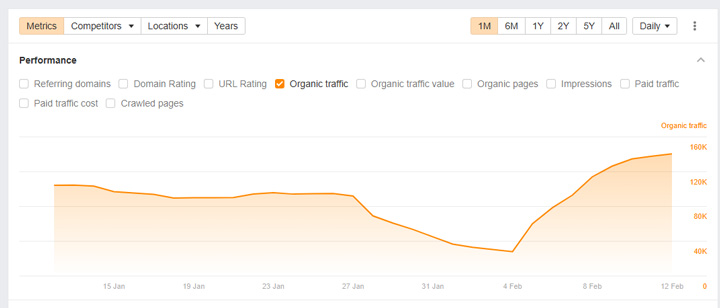
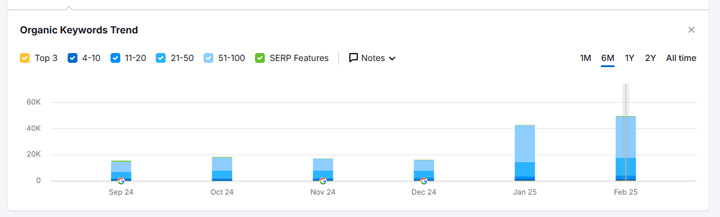
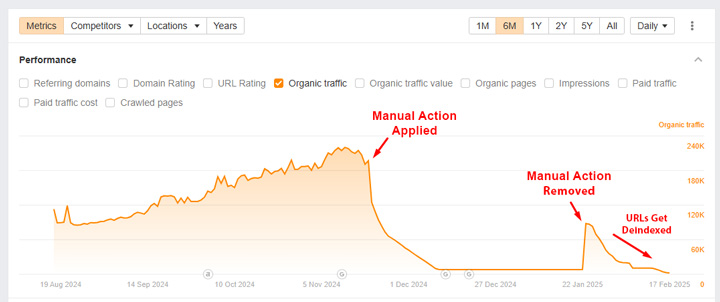
Below, you can see visibility tank when the site received the manual action but then rebound when the site started both disallowing via robots.txt and noindexing the content. I’m assuming the site had the manual action (incorrectly) removed when they did this. And since Google could not crawl the urls to see the noindex tag, the pages remained indexed, but just without Google crawling the content.
And yep, the pages ranked… and ranked very well. Note, I’m not sure if this slipped by the webspam team, or disallowing via robots.txt was added after the manual action was removed. Regardless, the site started ranking very well again.
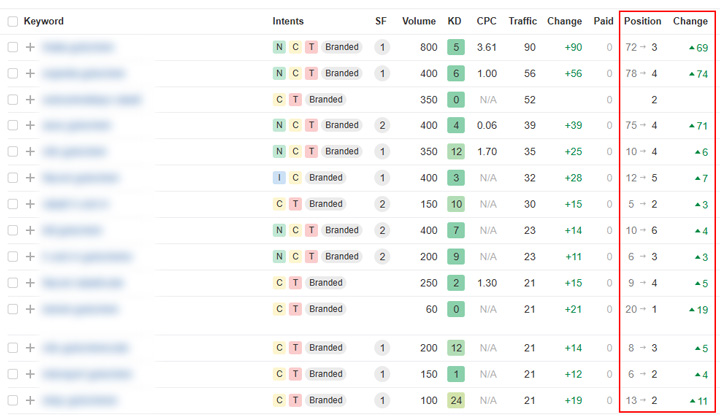
Here are some rankings for when the manual action was removed and the site jumped back into the SERPs with content violating Google’s site reputation abuse policy:
Update: March 12, 2025
Google updated its manual actions documentation explaining that disallowing is not a valid approach and that noindexing is the way to go. The documentation says, “To make sure your noindex rule is effective, don’t block that content with your robots.txt file.” I love that Google added this to the manual action docs… Hopefully this helps site owners avoid implementing the wrong changes (which could lead to additional manual actions).
2. Canonicalizing site reputation abuse content. NOT VALID
Nope, this is not a good idea. It’s also not recommended by Google for handling site reputation abuse. Yet, there are some sites canonicalizing urls that are violating Google’s site reputation abuse policy to either the top-level directory for that content, or to other urls. I guess their idea is that Google will follow the canonical hint and not index all of the site reputation abuse content.
But it’s important to understand that rel canonical is just a hint, and not a directive, so Google can choose to ignore the user-selected canonical and index the urls. And then if those urls are indexed, they can rank.
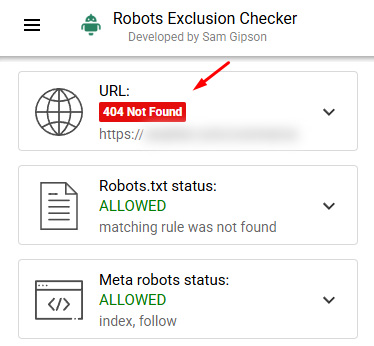
For example, here is a large and powerful site that has a directory of content violating Google’s site reputation abuse policy. All of the urls in that directory are canonicalized to another directory (the root url of that directory)… but that root url (the canonical page) is 404ing. Oof.
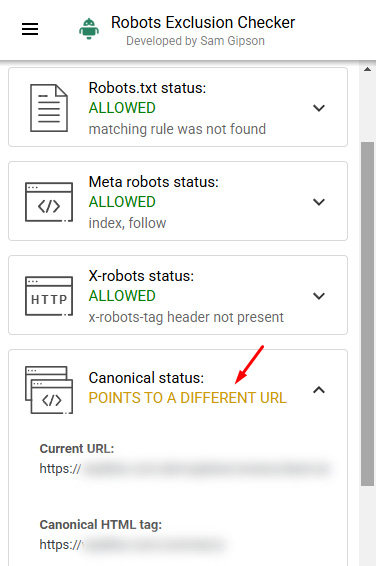
And the page those urls are all being canonicalized to 404s:
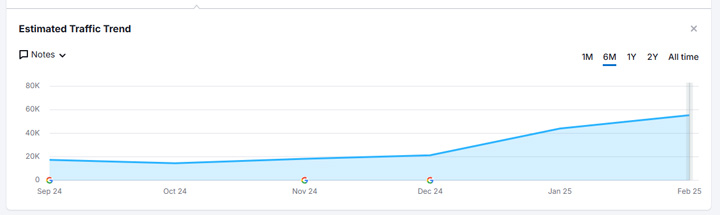
And Google has indexed urls in the directory and the folder ranks for over 50K queries. Again, this is not the correct way to handle site reputation abuse.
Now a correct method for handling content violating Google’s site reputation abuse policy:
3. Noindexing the content. VALID
If you noindex the content, Google will recrawl the urls and then remove them from the index. If removed from the index, they cannot rank. Mission accomplished.
Noindex is a directive and not a hint. You don’t have to worry about Google deciding what to do. It will remove the pages from the index once it recrawls the url and sees the noindex tag. And again, you shouldn’t noindex a url and also block it via robots.txt. Like I explained earlier, that can lead to the urls still being indexed, but just without Google crawling the content. That won’t happen if you just noindex the content, since Google will be able to crawl the urls and pick up the noindex tag.
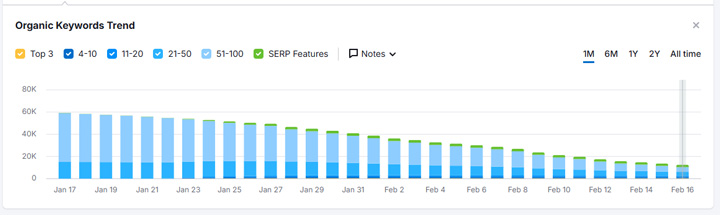
Here is an example of a site correctly noindexing all of the content in a directory that was violating Google’s site reputation abuse policy. Notice how the directory drops heavily when the manual action was applied. Then the site noindexed the content, filed a reconsideration request, and had the manual action removed. The directory actually surges back in the short term as Google hasn’t recrawled the urls yet containing noindex tags. But as Google recrawls more and more of the pages, they got removed from the index, and visibility drops heavily again for the directory.
This is the right approach. And again, Google just updated its manual actions documentation explaining that noindexing is the way to go, and to not disallow those urls via robots.txt.
Here are the number of keywords the section was ranking for dropping over time as Google recrawls the urls and sees the noindex tag (after the manual action was removed):
A note about specific user-agent blocking:
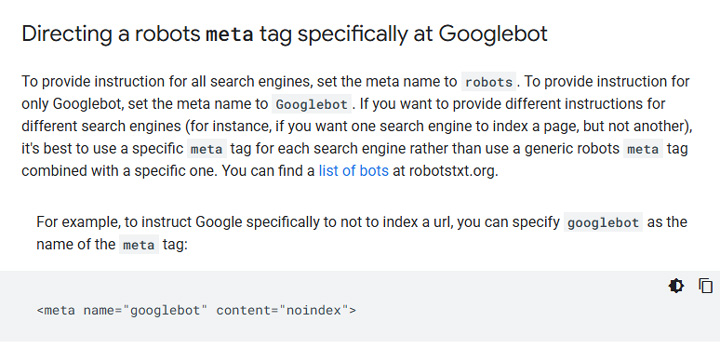
Also, you can always just noindex the urls for Google if you want. For example, if you still want the content to rank in Bing, or other search engines, then you can just noindex for Googlebot.
Here is information about blocking just Googlebot via the meta robots tag:
4. Nuking the content completely. 404s or 410s. VALID
I won’t spend much time covering this part. It’s straight forward… If you completely remove the content, or directory, then the content obviously can’t rank. Mission accomplished. File a reconsideration request and move on.
But I did want to point out that this is a big hammer and there are other traffic sources beyond Google. This is why some sites are choosing to noindex just for Google and not other engines. For example, you might choose to drive users to those sections via advertising, social media, or provide internal calls to action to those sections once users are already on your site. I’m not saying you should do this, but it’s definitely an option for publishers.
So removing the content fully via 404s or 410s is definitely a valid approach, but it might not make the most sense for some sites.
Here is a site that nuked all of the content in a directory that was violating Google’s site reputation abuse policy:
And you can see the massive drop in rankings over time as Google picked up the 404s. Again, it’s a big hammer, but a valid approach:
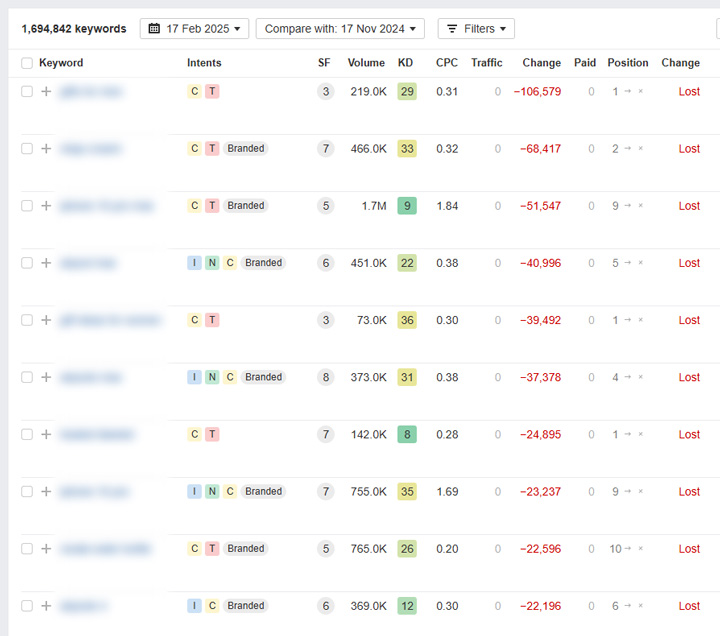
Summary: Know the right approach for handling site reputation abuse.
I hope this post cleared up any confusion you might have about the best approach for handling content that is violating Google’s site reputation abuse policy. If you need to block the content, make sure you do it correctly. And that means noindexing the content or fully removing it. Disallowing via robots.txt or canonicalizing the content are not valid methods. Both of those methods can lead to the content still being indexed and ranking in the SERPs. And if Google sees that, you either won’t have your manual action removed, or it can be applied again. Good luck.
GG